Dadosfera Library | Processar | Documentação Dadosfera
Esta biblioteca foi projetada para facilitar a extração, processamento e análise de dados a partir de diversas fontes - dentro e fora da Dadosfera, como:
- Buscar dados dos buckets S3 e Snowflake da Dadosfera;
- Criar e buscar dados de nosso Catálogo;
- Integrar com APIs como OpenAI;
- Ela oferece uma interface modular que permite interagir com essas fontes de maneira simples e eficiente, focando em tarefas comuns como coleta de dados, parsing de HTML e comunicação com APIs externas.
O fluxo geral de uso da biblioteca envolve a conexão com diferentes provedores de dados, a obtenção de informações, e a conversão desses dados em formatos prontos para análise ou integração com outros sistemas, usando os padrões da Plataforma Dadosfera. A biblioteca também inclui funcionalidades para estruturar dados em datasets e facilita a manipulação de grandes volumes de informações armazenadas na nuvem.
Além da Dadosfera Library, disponibilizamos os Steps, que são uma coleção de scripts prontos para uso na Dadosfera.
Todas as interações são organizadas de forma a garantir a reutilização de funções e componentes, tornando o processo de manutenção e expansão da biblioteca mais simples.
Versão Disponível
Manter a versão da biblioteca sempre atualizada é essencial para garantir acesso às últimas funcionalidades, melhorias de performance e correções de segurança. A seguir, apresentamos diversas maneiras de verificar a versão mais recente da Dadosfera Library.
No módulo de inteligência da plataforma Dadosfera é possível verificar a versão da biblioteca que está instalada no ambiente do seu projeto.
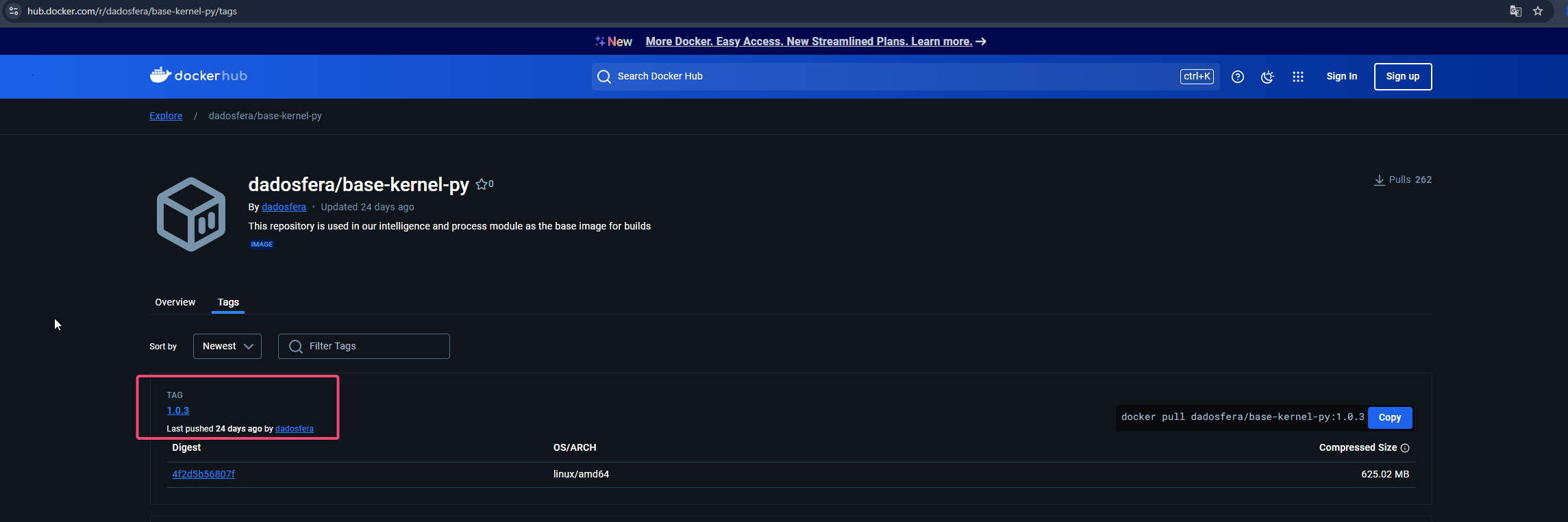
- Verifique a última versão lançada no docker hub: Image Docker Dadosfera Library
- Para isso, clique em
Tagse você verá algo semelhante a figura abaixo.
- No Jupyter Notebook digite o código abaixo pra verificar a versão instalada em seu ambiente. Ao executar o código você verá algo semelhante a figura abaixo.
!pip show dadosfera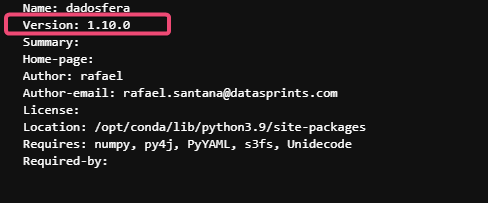
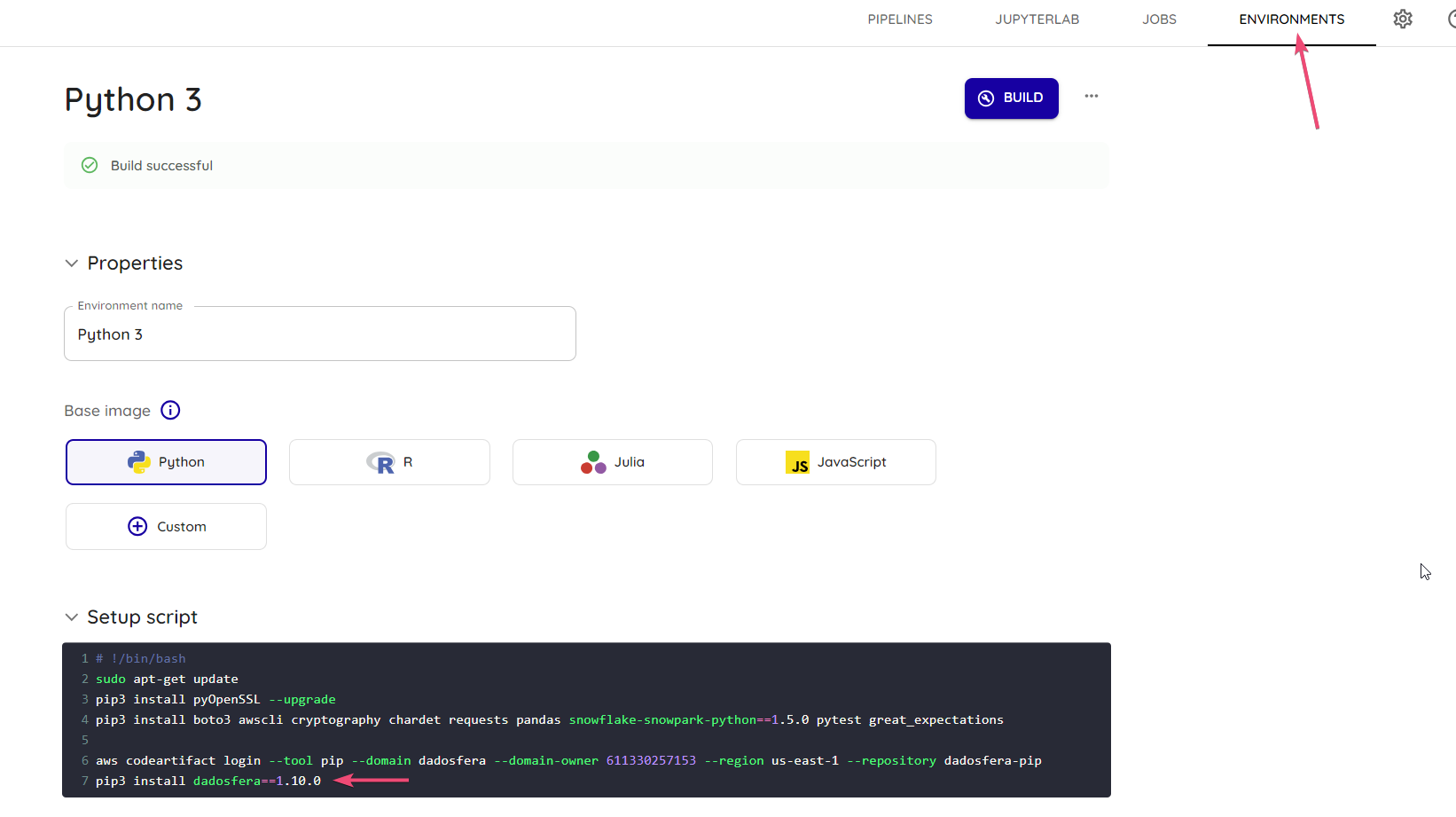
- Caso a versão do seu ambiente esteja desatualizada em relação a última versão disponibilizada no docker hub, siga as seguintes instruções:
- Clique em
Enviromentse na sessãoSetup scriptverifique a versão
- Visite o repositório oficial da biblioteca no GitHub Dadosfera Library Github para obter informações detalhadas sobre as versões lançadas.
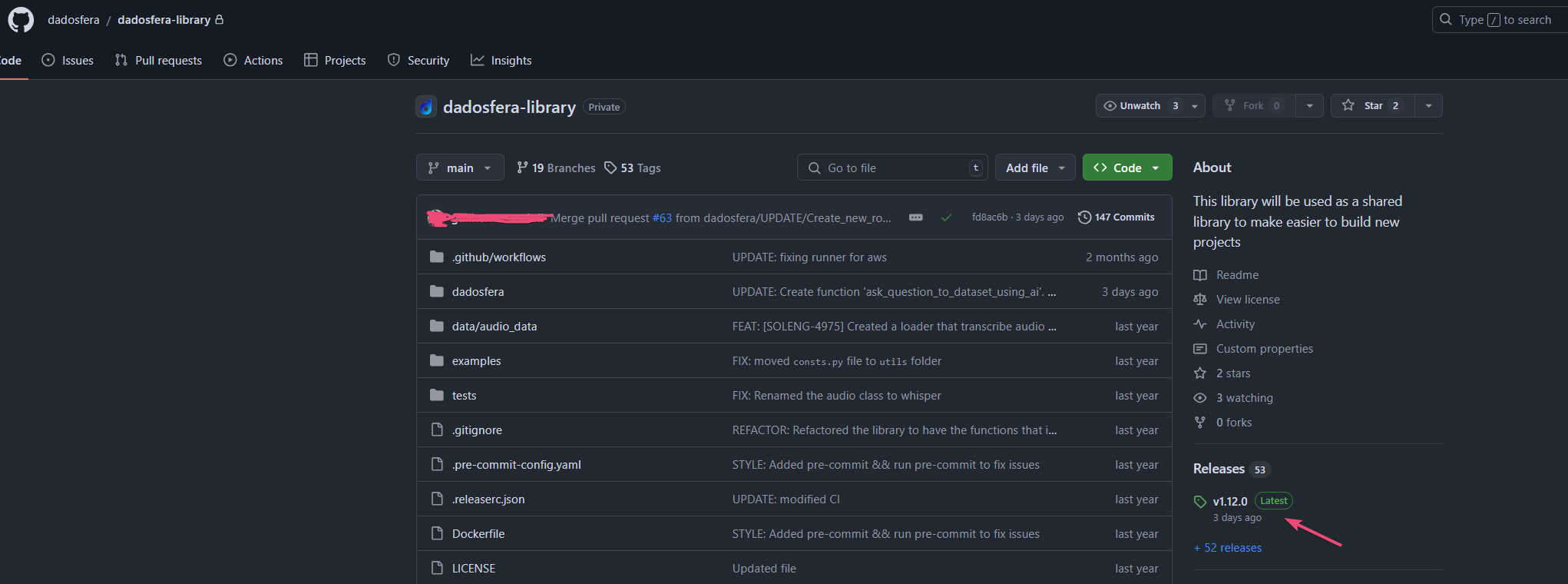
- Altere o código no
Setup scriptpara a última versão lançada no github. Em seguida clique emBuildpara atualizar .
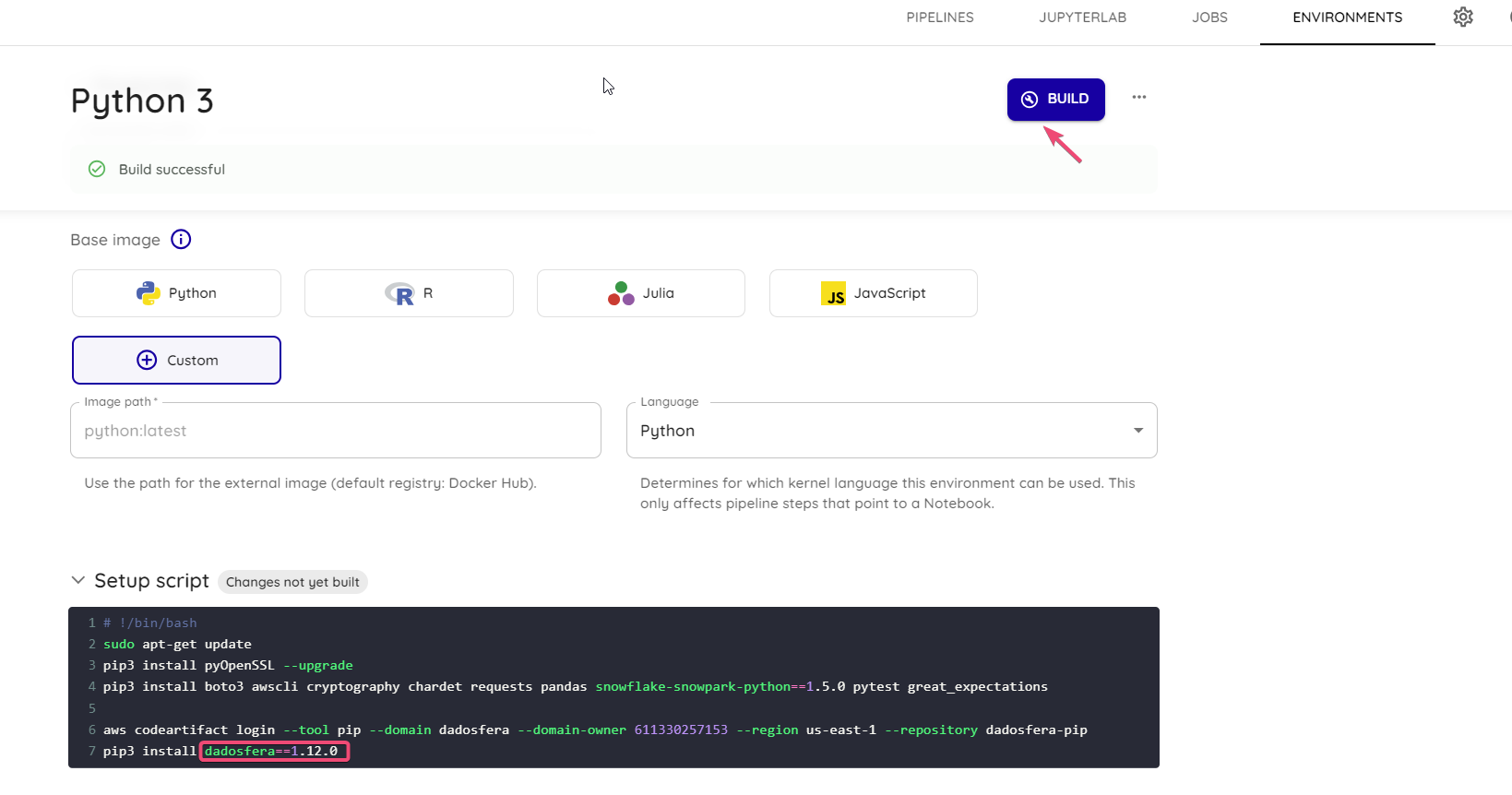
Pronto! Agora você pode usar as novas funcionalidades da Dadosfera Library.
- Caso ainda não tenha um ambiente configurado no seu projeto dentro do módulo de inteligência da plataforma Dadosfera, siga os passos descritos em Instalando a biblioteca da Dadosfera
Notas da versão
A imagem dadosfera/base-kernel-py:1.0.3 fornece um ambiente Python 3.8 com diversos pacotes de ciência de dados e desenvolvimento web. Ela foi projetada para funcionar com o módulo de inteligência e transformação da Dadosfera, uma plataforma para construir, executar e implantar pipelines de ciência de dados.
Pacotes Incluídos
Adições para Linux
- O Chrome Driver foi adicionado na imagem como uma dependência para ferramentas de web scraping, como o Selenium.
Pacotes Python
- awscli
- boto3
- snowflake-snowpark-python
- streamlit
- orchest
- dadosfera-library