Tutoriais | Processar | Documentação Dadosfera
Criando um Projeto
Você pode começar um projeto de 3 formas:
- Criando um novo projeto.
- Importando um projeto existente.
- Importando exemplos curados pela Dadosfera ou pela comunidade.
Criando e configurando Pipelines
Os pipelines são uma ferramenta interativa para criar e experimentar seu fluxo de trabalho de dados no Módulo. Um Pipeline é composto de etapas e conexões:
- As etapas são arquivos executáveis executados em seus próprios ambientes isolados.
- As conexões vinculam etapas para definir como os dados fluem (consulte passagem de dados) e a ordem de execução da etapa.
Os pipelines são editados visualmente e armazenados no formato JSON no arquivo de definição do pipeline. Isso permite que as alterações do Pipeline (por exemplo, adicionar uma etapa) sejam versionadas.
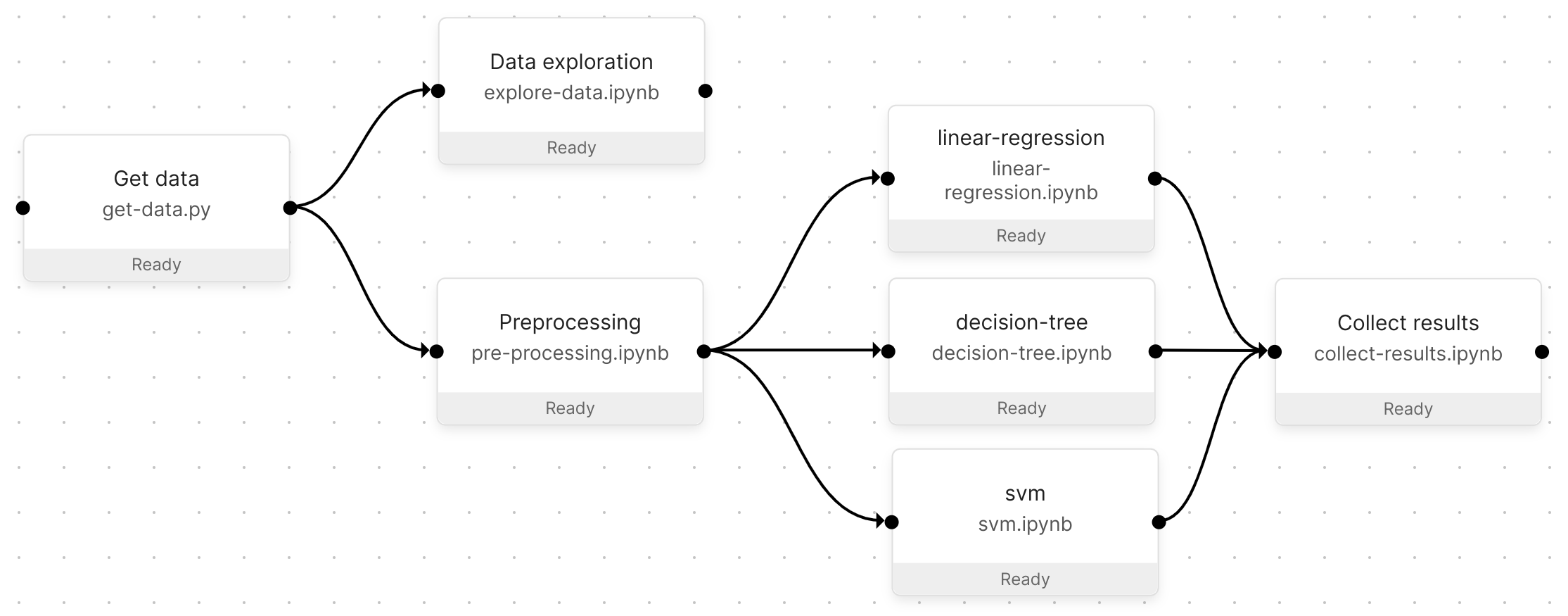
Exemplo de pipeline
Parametrizando Pipelines
Os pipelines usam parâmetros como entrada (por exemplo, a URL de conexão da fonte de dados) para variar seu comportamento. Os trabalhos podem usar parâmetros diferentes para iterar em várias execuções do mesmo pipeline. Os parâmetros podem ser definidos no editor de pipeline visual.
Você pode definir os parâmetros do Pipeline em dois níveis:
- Pipelines: os parâmetros e seus valores estarão disponíveis em todas as etapas do Pipeline.
- Etapas do pipeline: Os parâmetros só estarão disponíveis quando forem definidos.
Editando parâmetros de pipeline
- Abra um Pipeline através da opção Pipelines no painel de menu esquerdo.
- Clique nos três pontinhos no canto superior direito e selecione "Pipeline Settings".
- No menu que abrir, você encontrará a seção de parâmetros ("parameters") do Pipeline do lado direito.
- Insira algum JSON na estrutura
"chave : valor," como \{"my-param": <param-value>}. - Certifique-se de salvar na parte inferior da tela.
Editando os parâmetros da etapa do pipeline
- Abra um Pipeline através da opção Pipelines na barra de navegação.
- Clique em uma etapa do pipeline para abrir suas propriedades.
- Na aba "Properties", na parte inferior, você encontrará a seção de Parâmetros ("parameters").
- Insira algum JSON na estrutura
"chave : valor", como \{"my-param": <param-value>}.
Criando Environments
Os ambientes definem as condições em que os passos do pipeline executam scripts e kernels. Os ambientes são:
- Escolhidos no painel de propriedades do passo do pipeline no editor de pipelines.
- Configuráveis através do script de configuração (na página de ambientes) para instalar pacotes adicionais.
- Versionados e pertencentes a um único projects.
Escolhendo uma linguagem de programação na Dadosfera
Um ambiente usa apenas uma linguagem de programação para evitar a sobrecarga da imagem do contêiner com muitas dependências. O Módulo tem suporte integrado para ambientes com as linguagens:
- Python
- R
- JavaScript
- Julia
Cada ambiente suporta scripts Bash para invocar qualquer outra linguagem indiretamente. Por exemplo: Java, Scala, Go ou C++.
Para criar o ambiente:
- Vá para a página Environments.
- Crie um novo Ambiente.
- Escolha um nome de Ambiente.
- Escolha uma imagem base.
- Escolha uma das linguagens suportadas.
- Adicione comandos de instalação para pacotes adicionais no script de configuração do Ambiente.
- Pressione o botão Build.
Agendando jobs para sua pipeline
Após criar o Pipeline, codificar os arquivos, configurar suas etapas e configurar os Environments, inevitavelmente o Pipeline deve ser executado. Isso pode ser feito executando um Pipeline dentro do editor de pipeline ou por meio de Jobs. O primeiro permite teste fácil enquanto você está desenvolvendo seu Pipeline e o último (Jobs) permite que você execute seu Pipeline em produção em uma programação recorrente (por exemplo, diariamente). Veja abaixo o tutorial completo de como agendar seu pipeline.
Pré-requisitos
- Acesso ao Módulo de Transformação.
- Connection_parameters da conta Snowflake.
Passo a passo:
O procedimento para executar um trabalho parametrizado é muito semelhante à execução de um trabalho sem nenhum parâmetro. Depois de seguir qualquer um dos procedimentos acima para parametrizar seu pipeline:
- Certifique-se de ter definido os parâmetros básicos da Pipeline.
- Clique em Jobs no painel de menu à esquerda.
- Clique no botão + new job para configurar seu trabalho.
- Escolha um Job name e a Pipeline que deseja executar o job.
- Seu conjunto padrão de parâmetros é pré-carregado. Ao clicar nos valores, um editor JSON é aberto, permitindo que você adicione valores adicionais que deseja que a Pipeline execute.
- Se você quiser agendar o trabalho para ser executado em um horário específico, dê uma olhada em Scheduling.
- Pressione Run job.
Tour guiado:
Importar a lib Dadosfera versão Snowpark
Biblioteca intuitiva para consultar e processar dados em escala no Snowflake. Atualmente, o Snowflake fornece bibliotecas Snowpark para três idiomas: Java, Python e Scala, complementares à interface SQL original do Snowflake.
Para importar a lib no Módulo de Transformação da Dadosfera, siga os passos abaixo:
1 - Criar uma pasta chamada dadosfera na raiz do projeto.
2 - Criar um arquivo chamado snowflake.py dentro da pasta dadosfera.
3 - Colocar esse conteúdo no arquivo:
import os
import pandas as pd
from snowflake.snowpark import functions as F
import orchest as utils
connection_parameters = {
"user": os.environ.get('SNOWFLAKE_USER'),
"password": os.environ.get('SNOWFLAKE_PASSWORD'),
"account": os.environ.get('SNOWFLAKE_ACCOUNT'),
"warehouse": 'COMPUTE_WH',
"database": os.environ.get('SNOWFLAKE_DATABASE'),
"schema": 'PUBLIC',
}
def create_pandas_df(snowpark_df):
rows = snowpark_df.collect()
data = []
for row in rows:
data.append(row.as_dict())
df = pd.DataFrame(data)
for column in df.columns:
df = df.rename({column: column.lower()}, axis=1)
return df
def remove_quotes_from_columns(df, columns):
clean_function = [
F.trim(F.replace(column, '"', ''))
for column in columns
]
df = df.with_columns(columns, clean_function)
return df
def empty_string_as_null(df, columns):
empty_string_as_null_columns = [
f"nullif({column}, '') as {column}"
for column in columns
]
df = df.selectExpr(*empty_string_as_null_columns)
return dfCaso você ainda não possua os connection_parameters da sua conta Snowflake, solicite ao [email protected].
4 - As variáveis podem ser setadas a nível de pipeline da seguinte forma:
Clica nos ... -> Pipeline Settings -> Environment Variables
5 - Importante dar o start novamente no kernel do notebook para que as novas variáveis sejam utilizadas.
6 - Restaure a sessão.
Pronto! A lib está pronta para ser utilizada.
Configuração de notificações
Você pode receber notificações de webhook quando eventos específicos ocorrem no Módulo. Por exemplo, quando uma tarefa falha. Sempre que um evento é acionado, a Dadosfera enviará uma solicitação HTTP para o seu endpoint desejado com um payload de informações. Por exemplo:
{
"delivered_for": {
"name": "Test webhook",
"verify_ssl": false,
"content_type": "application/json",
"uuid": "a1edb89c-1cfb-4086-8f75-ab073612c5bf",
"type": "webhook"
},
"event": {
"type": "ping",
"uuid": "08bd2a31-9b17-4d1b-83ba-b4538a970dee",
"timestamp": "2022-06-02 16:12:25.242592+00:00"
}
}Para criar um webhook, acesse "Configurações de notificação". O diálogo do webhook solicitará o seguinte:
- URL do webhook: onde a Dadosfera envia as solicitações HTTP. Ative os webhooks de entrada no canal desejado (por exemplo: Slack) e verifique a conexão com o botão "Testar".
- Tipo de conteúdo: application/json (padrão) ou application/x-www-form-urlencoded.
- Nome do webhook (opcional): um nome personalizado para seu webhook. Isso é útil ao criar vários webhooks com URLs semelhantes.
- Segredo (opcional): uma string secreta que você pode usar para verificar a origem da solicitação (consulte {ref}abaixo <secure_webhook>).
Verificando o webhook
O seguinte código de exemplo verifica se a assinatura do payload é a mesma que a esperada pelo segredo do webhook armazenado:
import hashlib
import hmac
import os
def verify_signature(payload, request_headers):
"""
Verifica se a assinatura do payload é a mesma
que a esperada pelo segredo do webhook armazenado.
"""
if not isinstance(body, bytes):
body = body.encode("utf-8")
digest = hmac.new(
os.environ["WEBHOOK_SECRET"].encode("utf-8"),
body,
hashlib.sha256
)Habilitando extensões no JupyterLab
AI Magic Function - Conectando o Jupyter notebook no ChatGPT
No environment do orchest, faça a instalação dos seguintes pacotes:
- jupyter_ai_magics
- jupyter_ai
Construção do ambiente
- Vá para a seção de Environments do projeto em que está atuando, como pode ser observado na imagem abaixo:
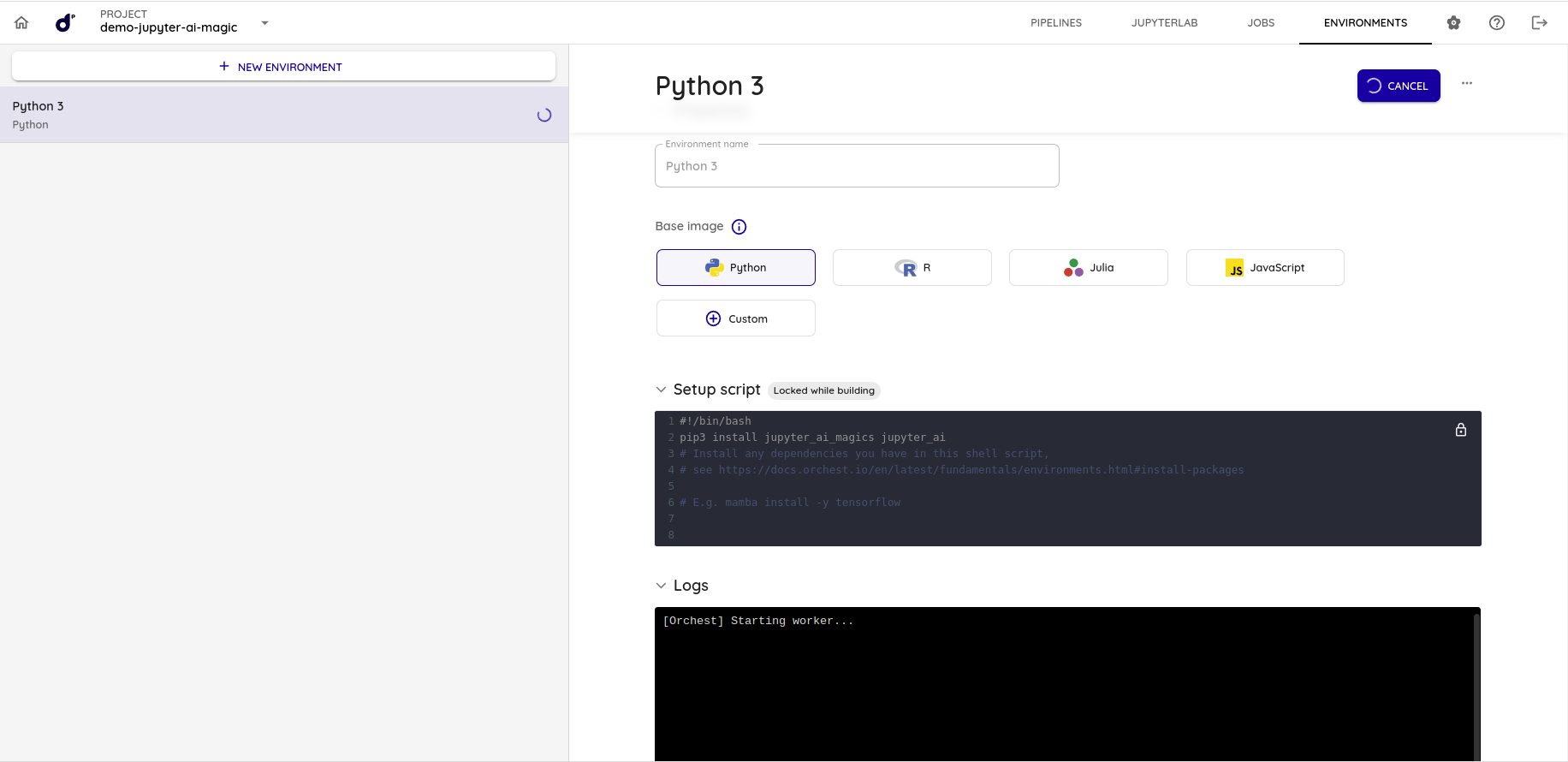
- Coloque o seguinte código no script que será executado ao construir o ambiente:
pip3 install jupyter_ai_magics jupyter_ai- Realize a construção do environment clicando no botão Build.
- Aguarde a construção do environment.
Setup das chaves da OpenAI
- No canto superior direito, clique no menu "...".
- Clique na opção Pipeline Settings
- Clique na opção Environment Variables
- Coloque uma variável de ambiente chamada
OPENAI_API_KEYcontendo uma chave de acesso a API da OpenAI. - Reinicie a sessão do projeto.
Setup do JupyterLab
- Entre no JupyterLab clicando no botão JUPYTERLAB no canto superior direito.
- Crie um Jupyter Notebook
- Dentro de uma célula de código, coloque o seguinte trecho de código e execute a célula para realizar o carregamento da extensão.
%load_ext jupyter_ai- Para fazer perguntas para o ChatGPT de dentro do Jupyter Notebook, basta usar a magic function
%%ai chagptcomo pode ser visto na imagem abaixo:
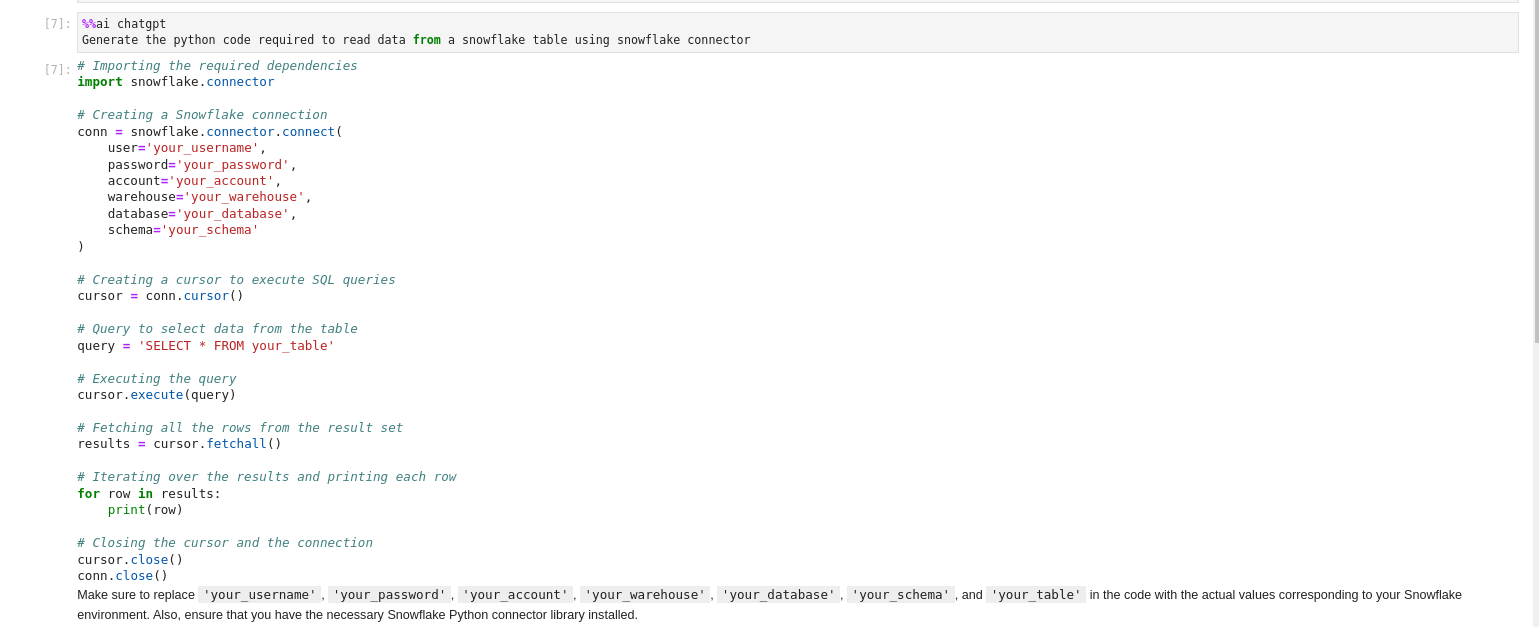
Jira Transformation Pipeline
Suponha que você tenha um JSON como exemplo proveniente do Jira, e deseje desagrupá-lo em campos individuais para facilitar a análise e consulta dos dados.
Dicionários
"customfield_10415": {
"accountId": "5f8a0deb9dbd090069d0f270",
"accountType": "atlassian",
"active": true,
"avatarUrls": {
"16x16": "https://avatar-management--avatars.us-west-2.prod.public.atl-paas.net/5f8a0deb9dbd090069d0f270/36248fd2-fd48-4390-b010-3a441b4853e3/16",
"24x24": "https://avatar-management--avatars.us-west-2.prod.public.atl-paas.net/5f8a0deb9dbd090069d0f270/36248fd2-fd48-4390-b010-3a441b4853e3/24",
"32x32": "https://avatar-management--avatars.us-west-2.prod.public.atl-paas.net/5f8a0deb9dbd090069d0f270/36248fd2-fd48-4390-b010-3a441b4853e3/32",
"48x48": "https://avatar-management--avatars.us-west-2.prod.public.atl-paas.net/5f8a0deb9dbd090069d0f270/36248fd2-fd48-4390-b010-3a441b4853e3/48"
},Arrays
"attachment": [
{
"author": {
"accountId": "6378fc76489de2f7f4629a82",
"active": false,
"avatarUrls": {
"16x16": "https://avatar-management--avatars.us-west-2.prod.public.atl-paas.net/6378fc76489de2f7f4629a82/35cb0e2a-9389-4df0-9fa7-cee86bb94779/16",
"24x24": "https://avatar-management--avatars.us-west-2.prod.public.atl-paas.net/6378fc76489de2f7f4629a82/35cb0e2a-9389-4df0-9fa7-cee86bb94779/24",
"32x32": "https://avatar-management--avatars.us-west-2.prod.public.atl-paas.net/6378fc76489de2f7f4629a82/35cb0e2a-9389-4df0-9fa7-cee86bb94779/32",
"48x48": "https://avatar-management--avatars.us-west-2.prod.public.atl-paas.net/6378fc76489de2f7f4629a82/35cb0e2a-9389-4df0-9fa7-cee86bb94779/48"
},
"displayName": "Aline Amaral",
"self": "https://dadosfera.atlassian.net/rest/api/2/user?accountId=6378fc76489de2f7f4629a82",
"timeZone": "America/Sao_Paulo"
},
"content": "https://dadosfera.atlassian.net/rest/api/2/attachment/content/14989",
"created": "2023-01-23T16:55:18.458000Z",
"filename": "[JUR - CONT - RES - DOC098] - Contrato_de_Prestação_de_Serviços_e_lincenciamento _de_software_UnimedVR X DataSprints .pdf",
"id": "14989",
"mimeType": "application/pdf",
"self": "https://dadosfera.atlassian.net/rest/api/2/attachment/14989",
"size": 1792848
}
]Para desagrupar o dicionário mostrado, é necessário passar na query as chaves referentes aos dados. Utilizando o Snowflake e a linguagem SQL, o código seria:
Dicionários
SELECT
fields:customfield_10415:accountId AS customfield_10415_accountId,
fields:customfield_10415:accountType AS customfield_10415_accountType,
fields:customfield_10415:active AS customfield_10415_active,
fields:customfield_10415:avatarUrls:"16x16" AS customfield_10415_avatarUrls_16x16,
fields:customfield_10415:avatarUrls:"24x24" AS customfield_10415_avatarUrls_24x24,
fields:customfield_10415:avatarUrls:"32x32" AS customfield_10415_avatarUrls_32x32,
fields:customfield_10415:avatarUrls:"48x38" AS customfield_10415_avatarUrls_48x48,
fields:customfield_10415:displayName AS customfield_10415_displayName,
fields:customfield_10415:self AS customfield_10415_self,
fields:customfield_10415:timeZone AS customfield_10415_timeZone
FROM public.tb__fqtpnb__issuesArrays
SELECT
fields:attachment:author:accountId AS attachment_author_accountId,
fields:attachment:author:active AS attachment_author_active,
fields:attachment:author:avatarUrls:"16x16" AS attachment_author_avatarUrls_16x16,
fields:attachment:author:avatarUrls:"24x24" AS attachment_author_avatarUrls_24x24,
fields:attachment:author:avatarUrls:"32x32" AS attachment_author_avatarUrls_32x32,
fields:attachment:author:avatarUrls:"48x38" AS attachment_author_avatarUrls_48x48,
fields:attachment:author:displayName AS attachment_author_displayName,
fields:attachment:author:self AS attachment_author_self,
fields:attachment:author:timeZone AS attachment_author_timeZone,
fields:attachment:content AS attachment_content,
fields:attachment:created AS attachment_created,
fields:attachment:filename AS attachment_filename,
fields:attachment:id AS attachment_id,
fields:attachment:mimeType AS attachment_mimeType,
fields:attachment:self AS attachment_self,
fields:attachment:size AS attachment_size
FROM public.tb__fqtpnb__issuesEste código SQL desagrupa as informações contidas no campo customfield_10415 do JSON, tornando-as acessíveis em colunas individuais para facilitar a manipulação e análise dos dados no ambiente Snowflake. Certifique-se de ajustar conforme necessário para atender à sua configuração específica.
A mesma lógico é aplicada para os demais campos.
Updated 6 months ago