Subindo um Data App com Streamlit | Documentação Dadosfera
Abaixo você aprenderá o passo a passo de como utilizar o template disponibilizado pelo nosso time para subir Data Apps utilizando o Streamlit no Módulo de Inteligência.
Pré-requisitos
- Possuir usuário na Dadosfera;
- Acesso ao Módulo de Inteligência;
- Ter um projeto criado no Módulo de Inteligência.
Preparando o ambiente no módulo para o Data App
Na aba ENVIRONMENTS selecione a imagem Python e nomeie seu ambiente como preferir.
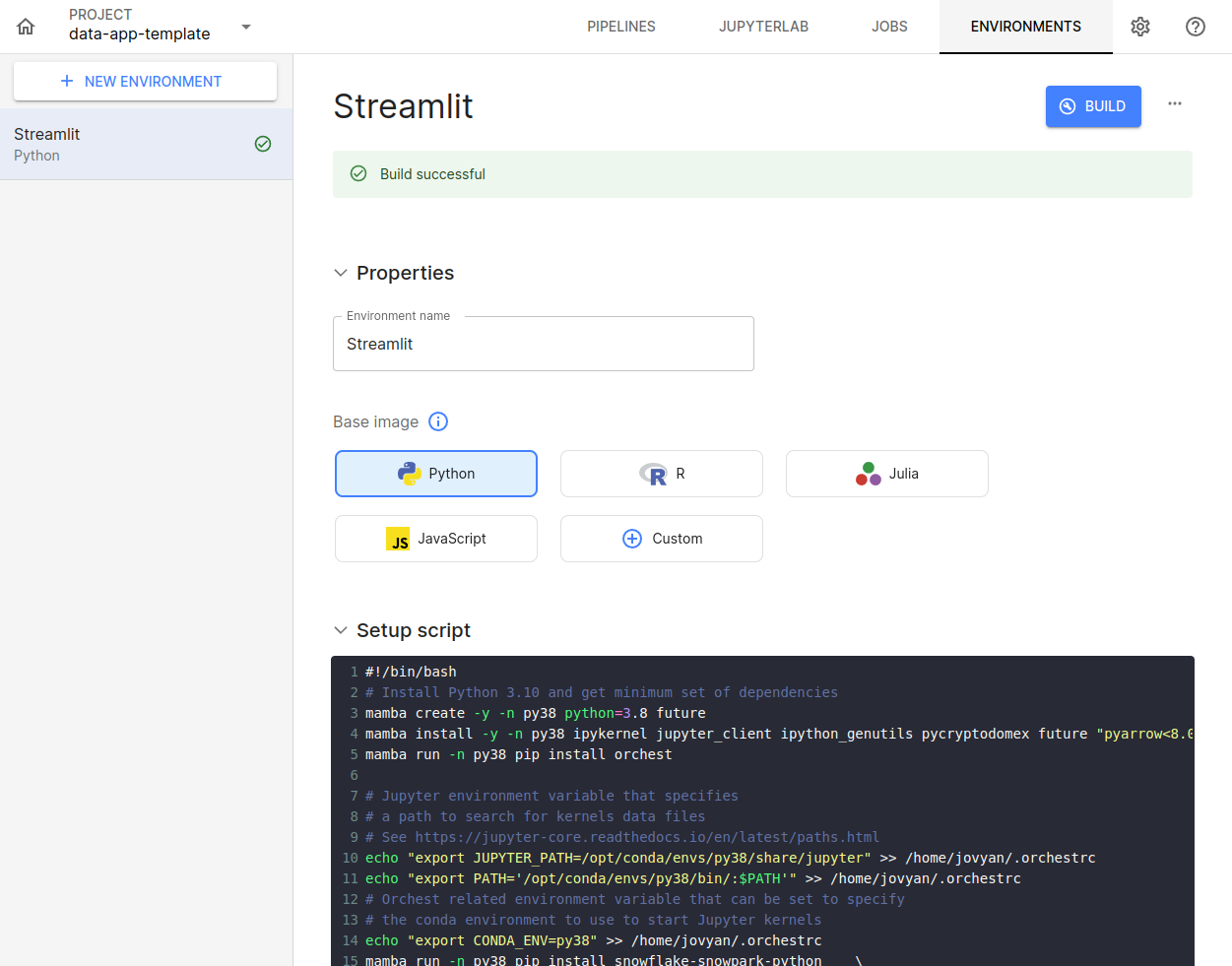
No campo Setup script cole o seguinte código:
#!/bin/bash
# Install Python 3.8 and get minimum set of dependencies
mamba create -y -n py38 python=3.8 future
mamba install -y -n py38 ipykernel jupyter_client ipython_genutils pycryptodomex future "pyarrow<8.0.0"
mamba run -n py38 pip install orchest
# Jupyter environment variable that specifies
# a path to search for kernels data files
# See https://jupyter-core.readthedocs.io/en/latest/paths.html
echo "export JUPYTER_PATH=/opt/conda/envs/py38/share/jupyter" >> /home/jovyan/.orchestrc
echo "export PATH='/opt/conda/envs/py38/bin/:$PATH'" >> /home/jovyan/.orchestrc
# Orchest related environment variable that can be set to specify
# the conda environment to use to start Jupyter kernels
echo "export CONDA_ENV=py38" >> /home/jovyan/.orchestrc
mamba run -n py38 pip install pandas snowflake-snowpark-python streamlit plotly
Esses são os requisitos base para um projeto de data app utilizando Streamlit, caso seja necessário mais algum recurso para rodar seu projeto, deve ser adicionado neste código.
Em seguida, acione o botão de build para que seu ambiente seja construído. O botão está localizado no canto superior direito da interface.
Para verificar se a construção rodou com sucesso, deve ter um retorno similar a esse:
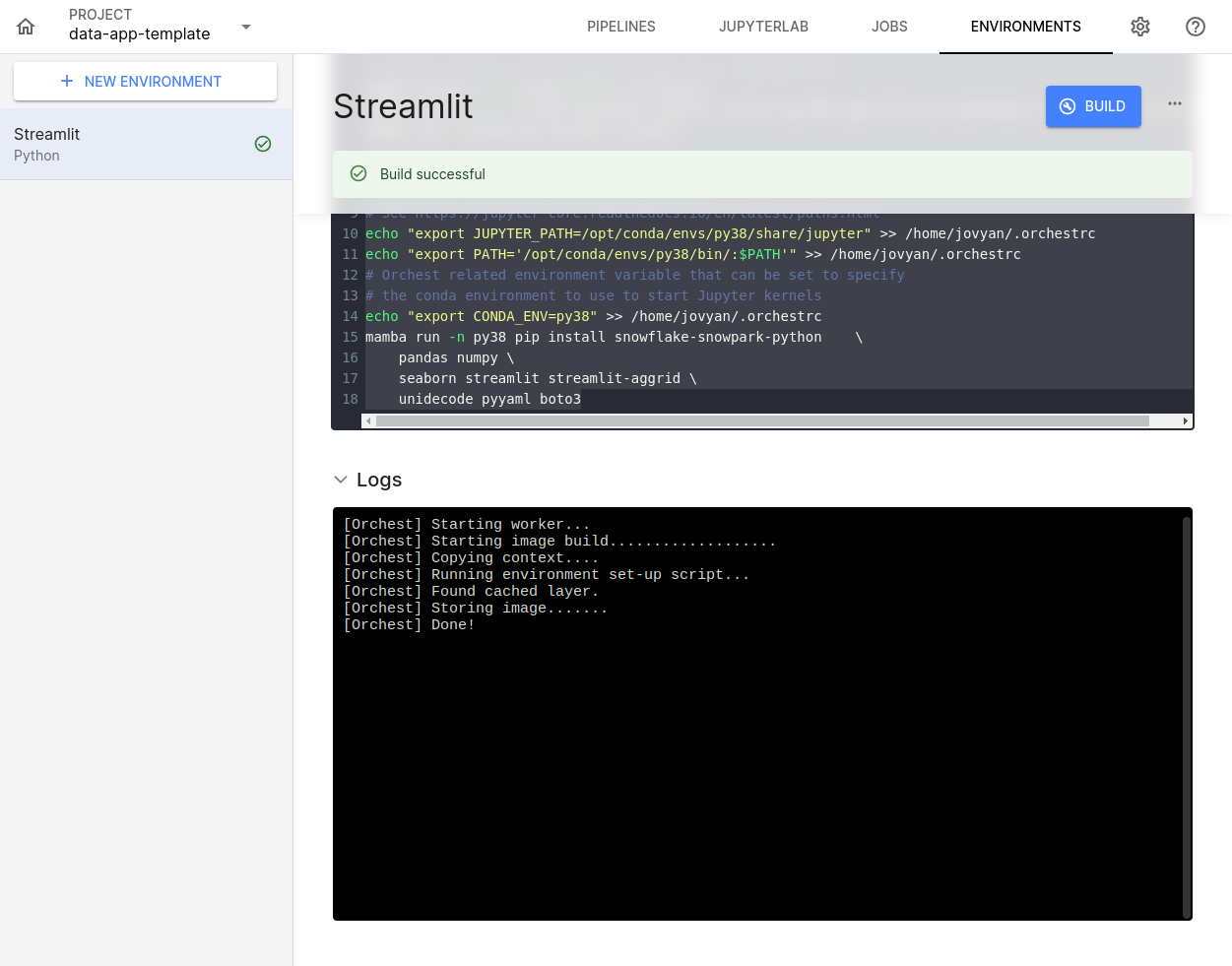
Feito isso o ambiente está pronto para rodar um data app com Streamlit.
Subindo o projeto de exemplo
Para baixar o projeto de exemplo, basta clicar no formato que preferir .zip ou .tar.gz.
Descompacte o arquivo baixado, selecione e faça upload da pasta app/ para o módulo:
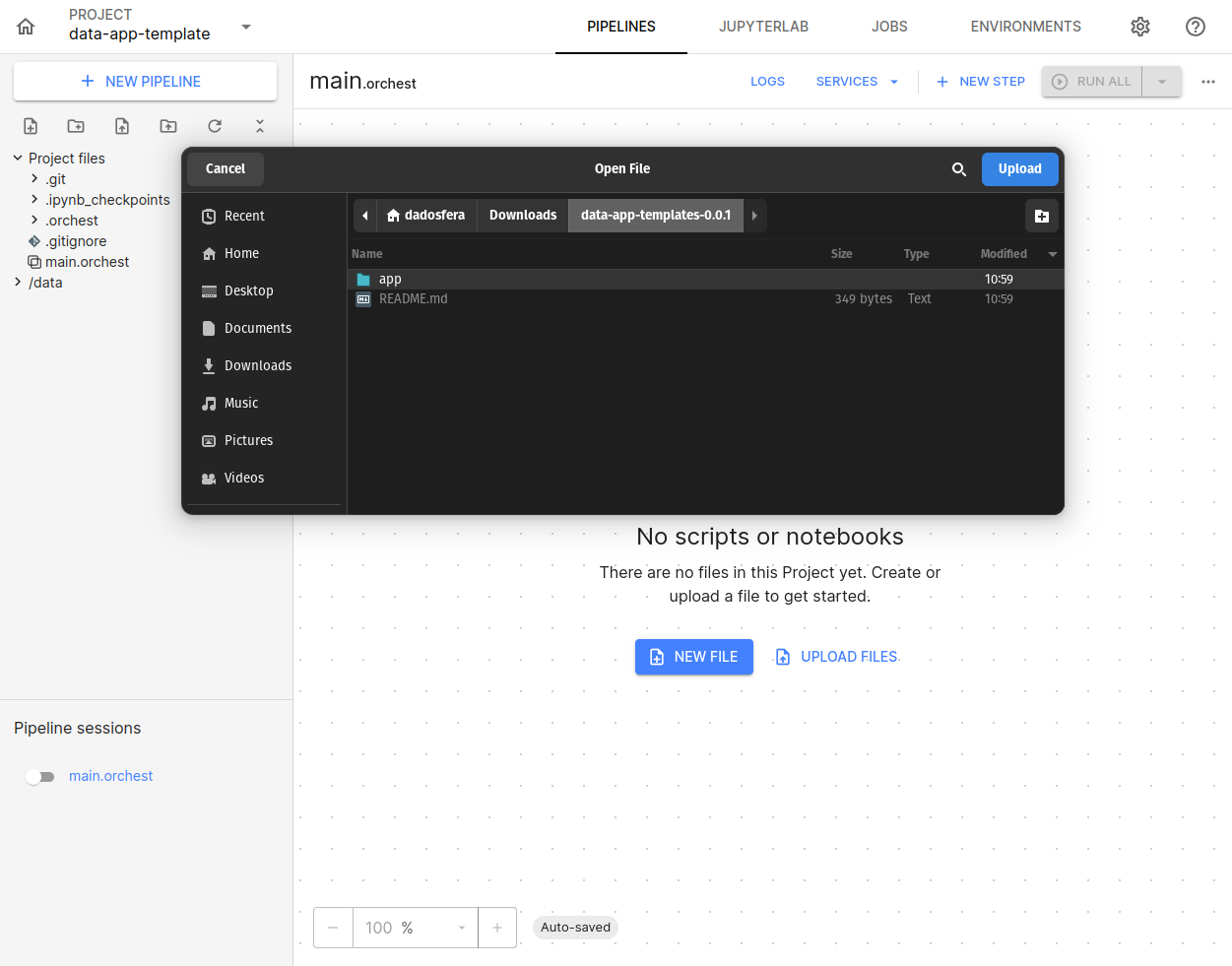
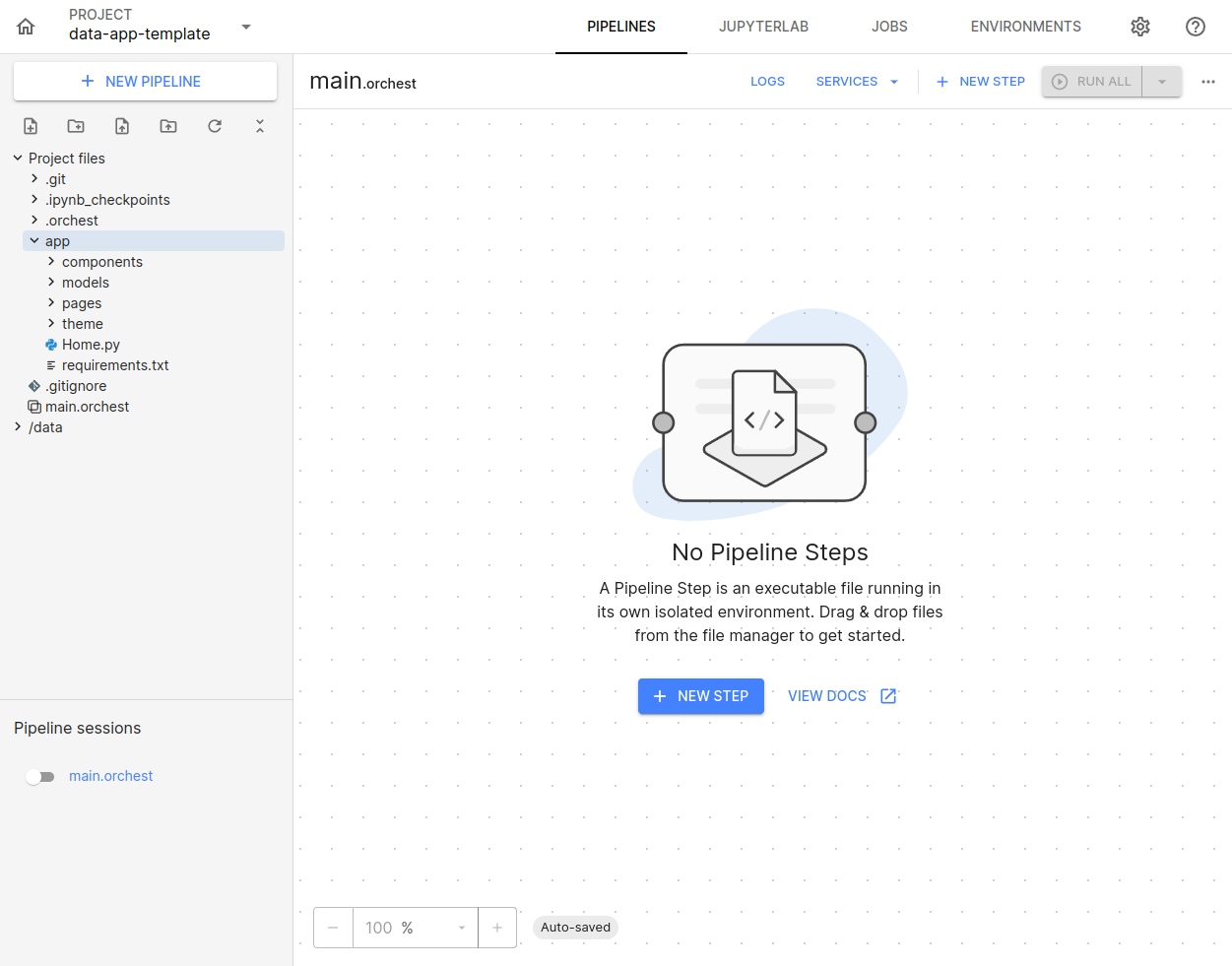
Feito isso o projeto já está preparado para virar um serviço do módulo.
Criando um SERVICE para o projeto em: Data Apps -> Edit Data Apps
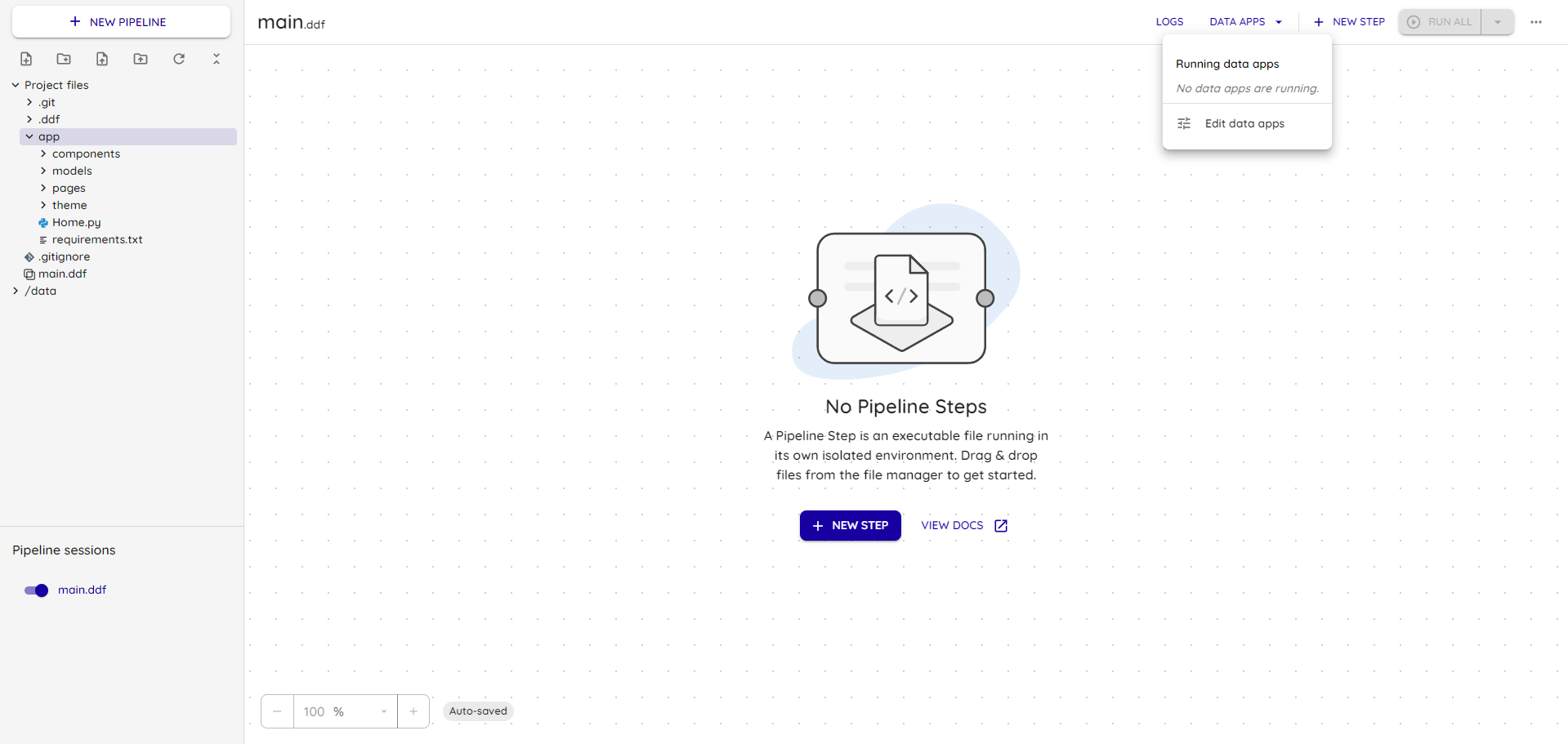
Adicione um novo serviço Streamlit em 'Add Service':
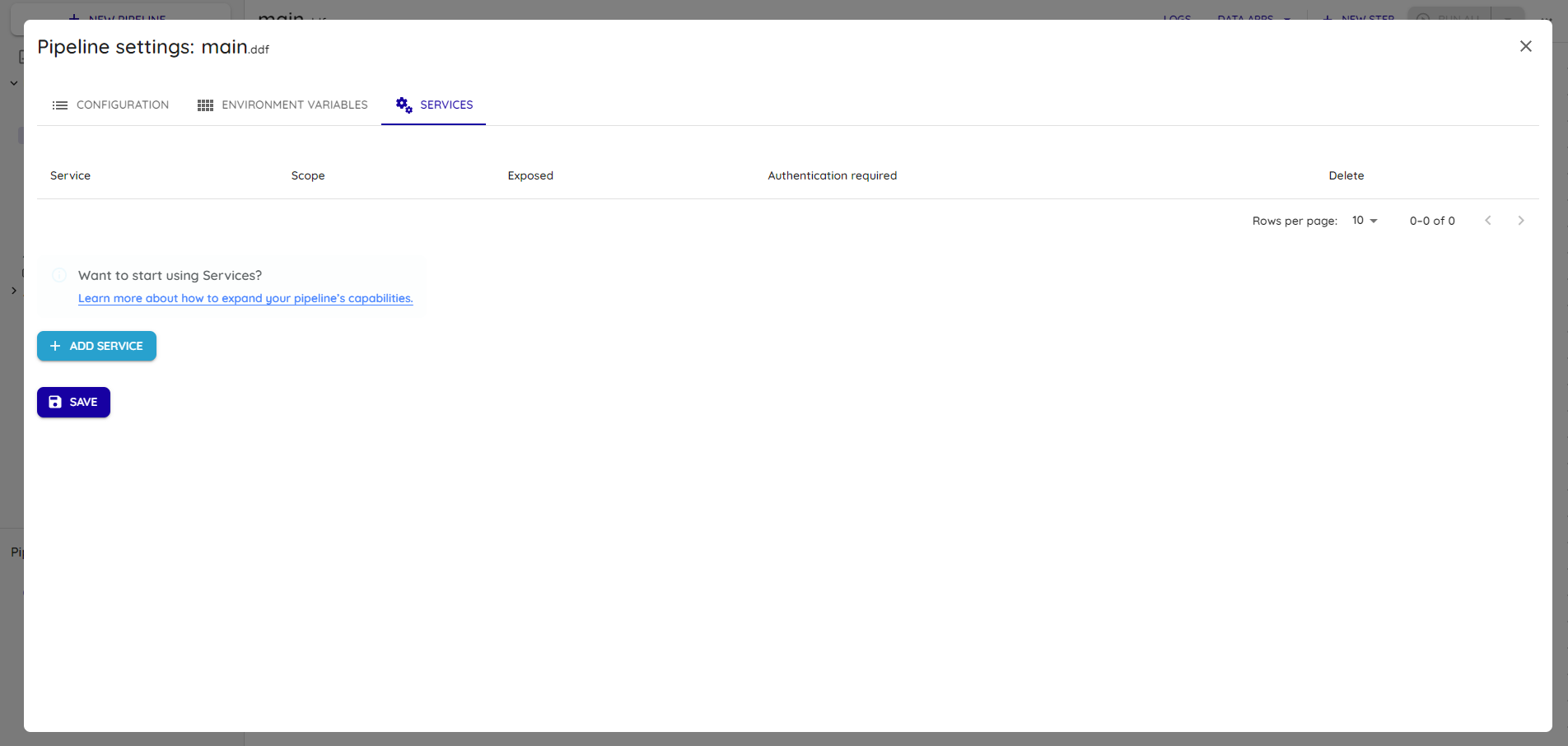
Selecione o Streamlit e espanda a linha criada com o nome do serviço: Streamlit.
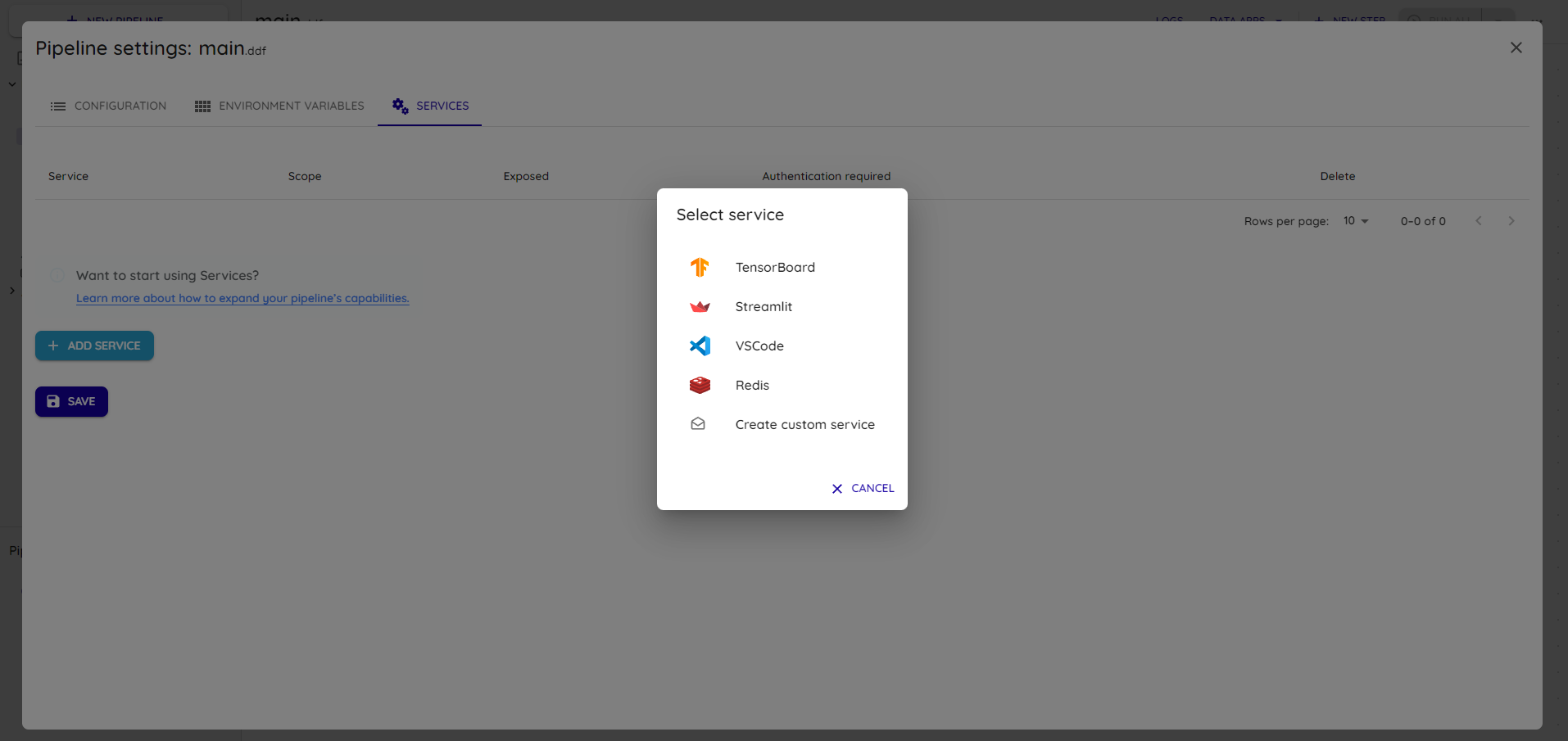
Aperte no campo Image e selecione a imagem do ambiente configurado anteriormente:
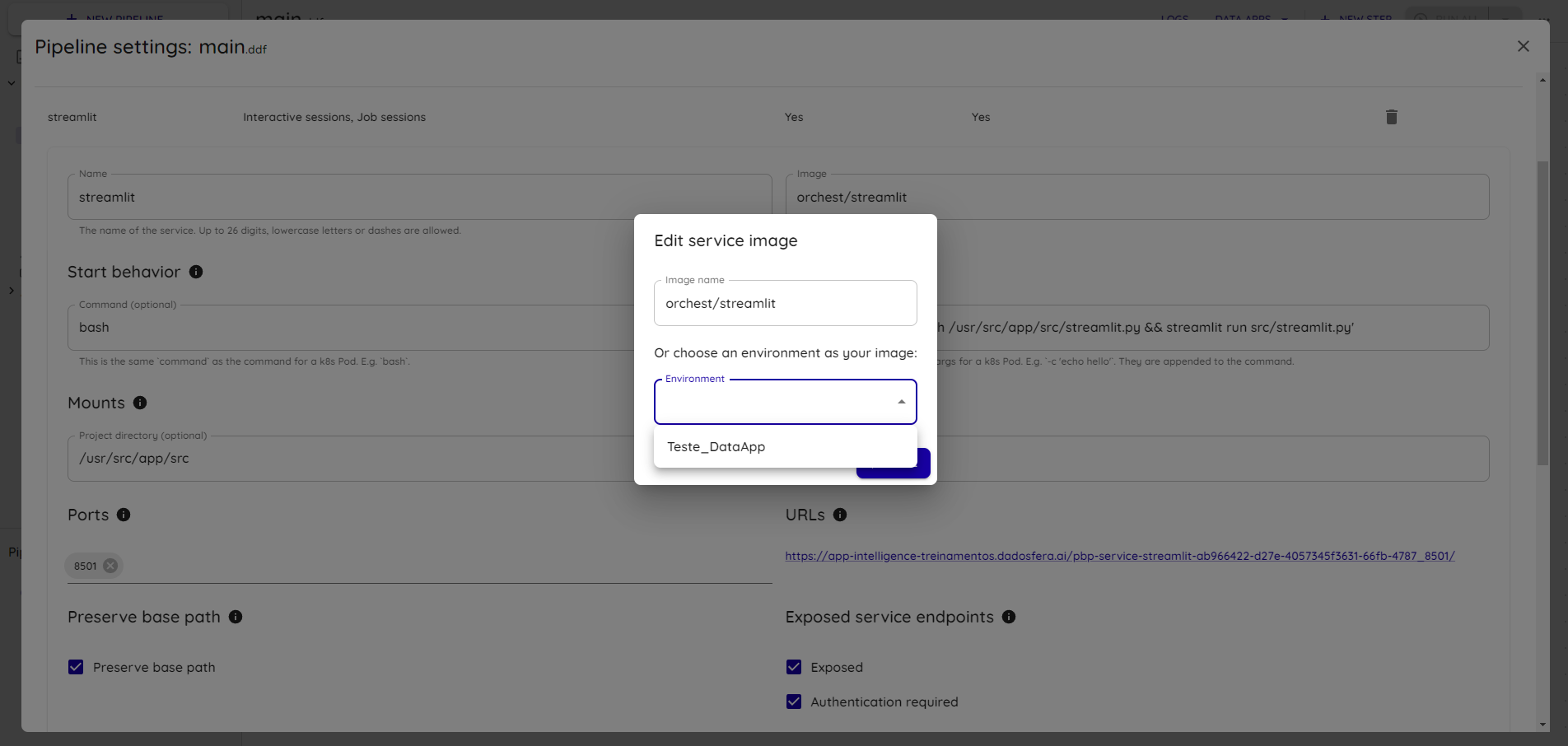
Configure o serviço com os seguintes valores:
Args: -c 'umask 002 && streamlit run app/Home.py'
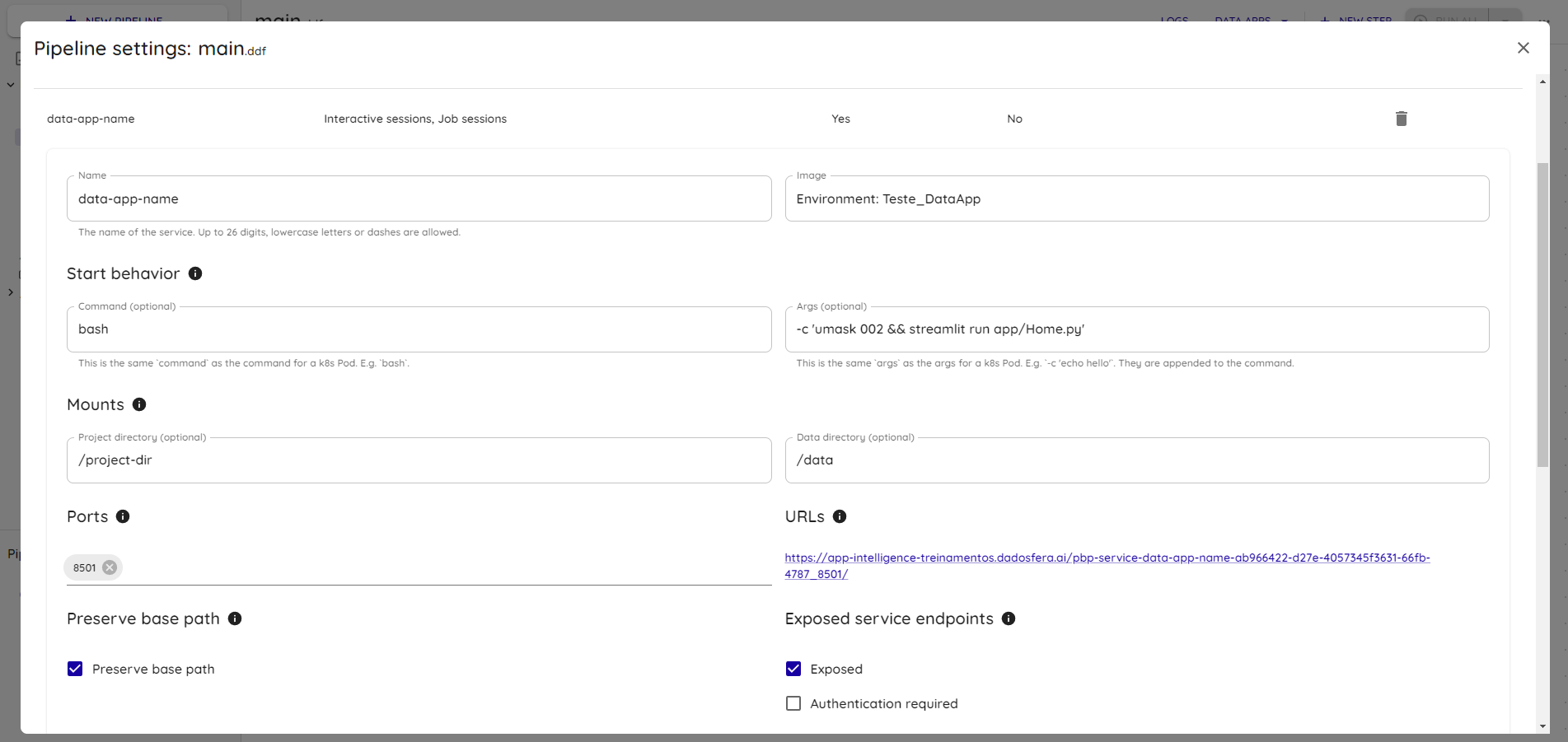
E salve as alterações:
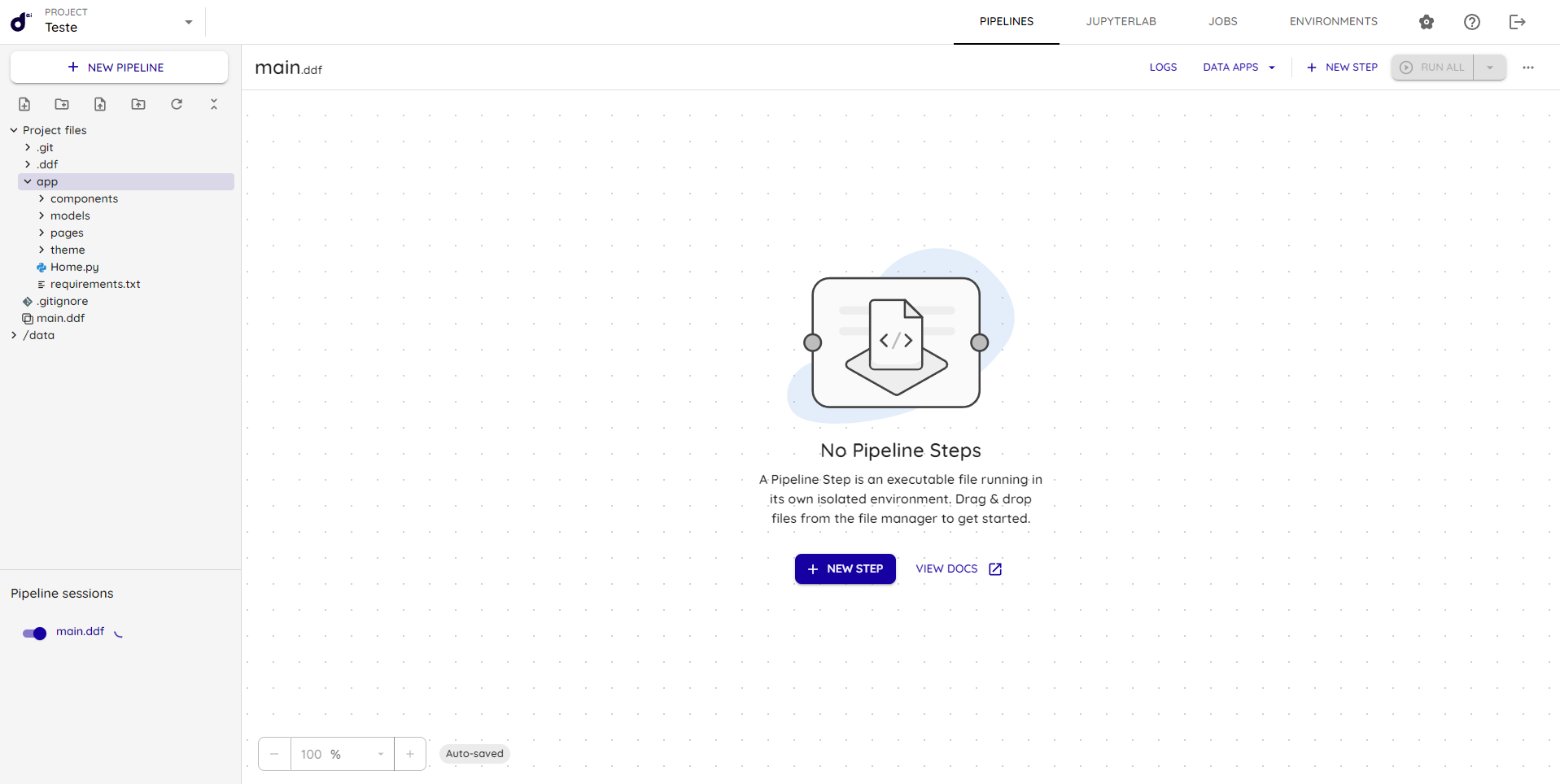
Feito isso basta voltar para a página de pipelines e reiniciar a sessão, como pode ser observado no canto inferior esquerdo, em pipeline sessions (main.ddf):
Acessando o serviço
Na aba SERVICES selecione o seu Data App:
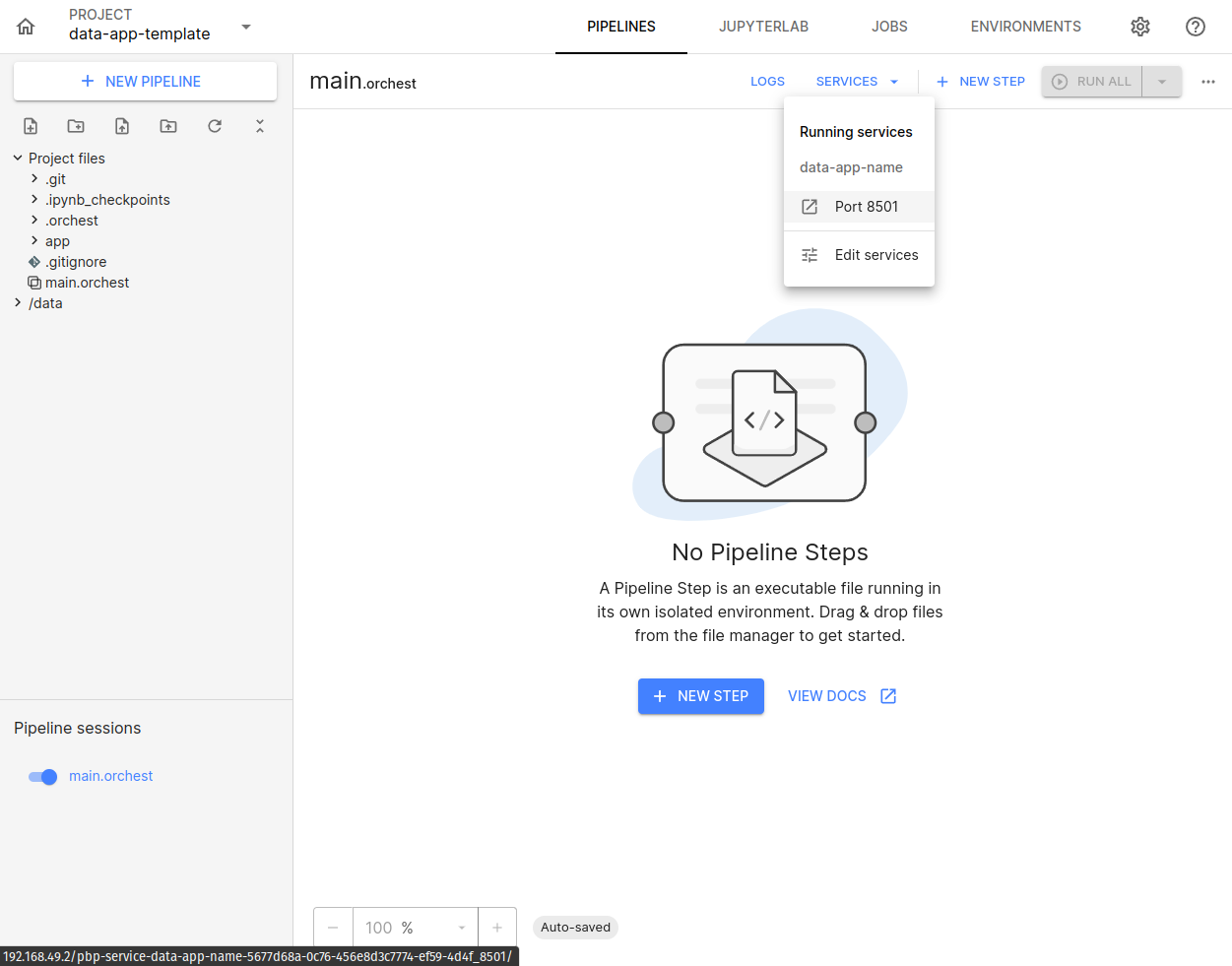
Pronto, você será redirecionado ao link de acesso ao seu Data App, com os componentes disponibilizados nesta template:

Vale ressaltar que alterar o nome do service nas configurações do mesmo impacta diretamente no link personalizado, portanto não recomendamos fazer alterações no nome depois do serviço já ter sido criado e compartilhado com outras pessoas e aplicações.
Observação
Na página de exemplos exibirá um erro:
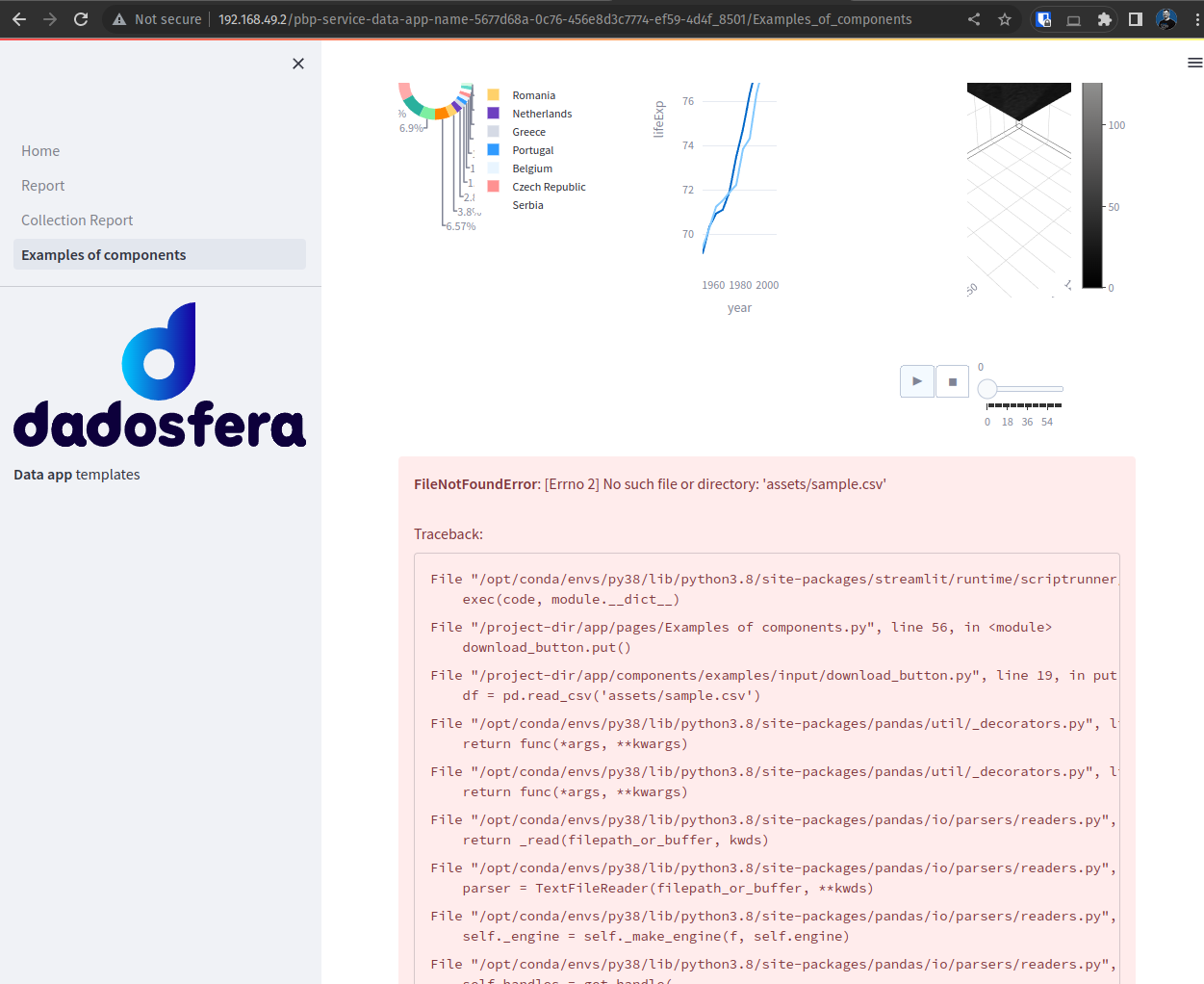
Esse erro foi provocado propositalmente para que você possa colocar seu próprio arquivo sample.csv na pasta do projeto e possa obervar o funcionamento do botão de download como mostrado abaixo.
Uma vez com o template no seu ambiente, basta editar os scripts diretamente pelo Jupyter de acordo com o projeto que será realizado. Todo o projeto foi desenvolvido visando o reaproveitamento de código portanto está separado em componentes de exemplo, componentes de aplicação e páginas, além de possuir um modelo de entidade para simular a interação com dados reais.
Qualquer dúvida ou sugestão, entre em contato com o nosso time.
Updated 6 months ago