Pipelines | Coletar | Documentação Dadosfera
O que é uma pipeline?Data pipeline é o processo em que os dados de uma origem são direcionados para um destino com ou sem processamento e transformação prévia. Na Dadosfera, utilizamos o paradigma EL(T).
Uma Pipeline na Dadosfera tem suas métricas de monitoramento e propriedades específicas, como nome, descrição, status e histórico de execução.
A coleta de dados recorrente em batch (lotes) é feita por meio da criação de uma pipeline, determina a partir da seleção de uma fonte, para a evolução dos dados coletados dentro da Plataforma nas etapas seguintes.
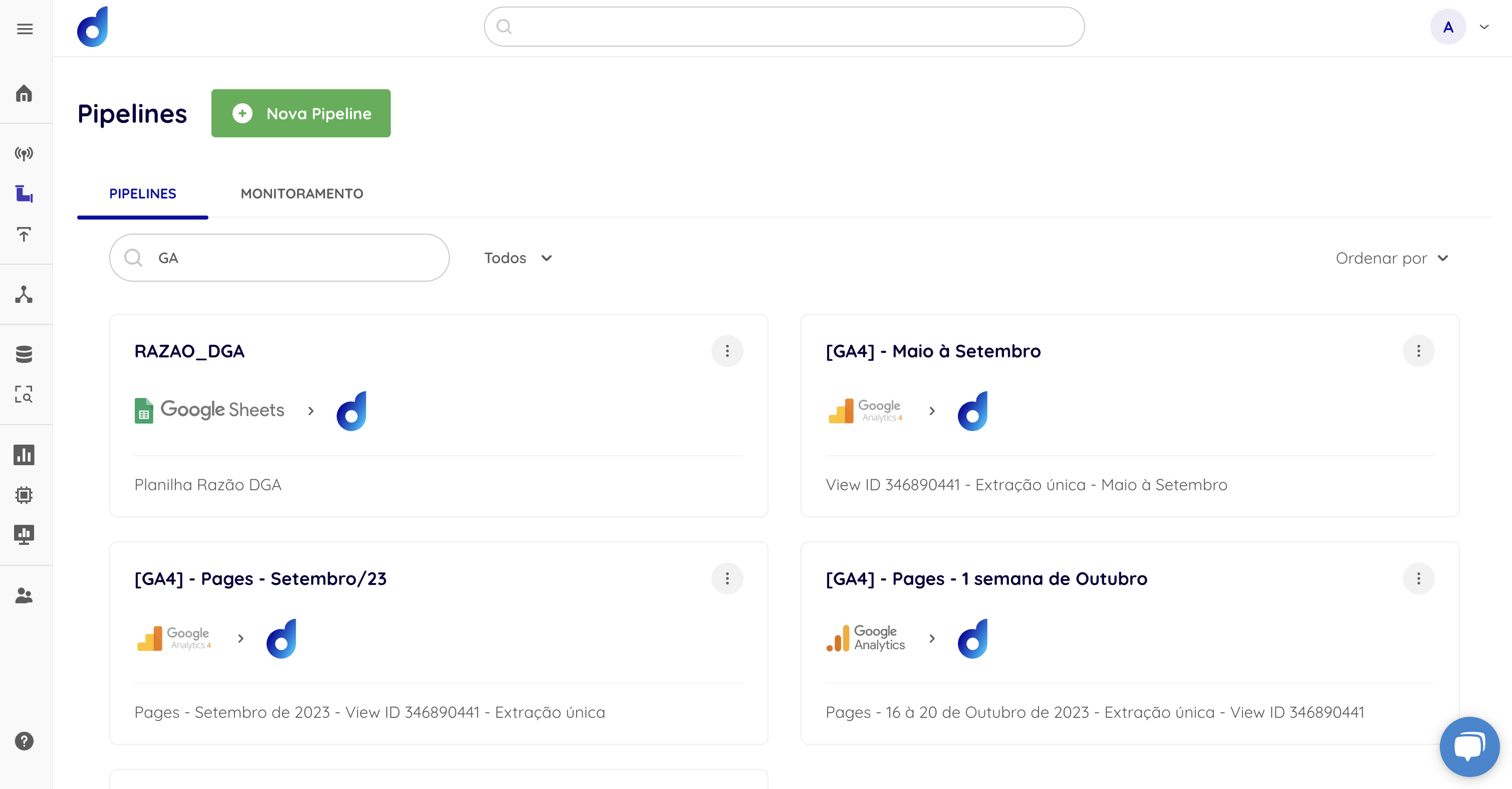
Tela de Gerenciamento de Pipelines
Etapas
O carregamento dos dados na Plataforma consiste basicamente em:
- Cadastrar ou escolher uma fonte de dados cadastrada;
- Definir as informações gerais da pipeline;
- Inserir as configurações da pipeline (que variam de acordo com o tipo de fonte);
- Definir as entidades, colunas e modo de sincronização (que varia de acordo com o tipo de fonte);
- Criar micro-transformação (opcional);
- Escolher a frequência da coleta.
Dados suportados
| Classificação | Tipo de dados |
|---|---|
| Numéricos | number, decimal numeric, int, integer, bigint, smallint, byteint, float, float4, float8, double, double precision, real |
| String e binários | varchar, char, character, string, text, binary, verbinary |
| Lógicos | boolean |
| Data e hora | date, datetime, time, timestamp, timestamp_ltz, timestamp_ntz, timestamp_tz, |
| Semiestruturados | variant, object, array |
| Geoespaciais | geography |
Dados não suportados
| Classificação | Tipo de dados |
|---|---|
| LOB (Large Object) | blob, clob |
| Outros | enum, user-defined data type |
Para saber mais sobre os tipos de dados suportados, acesse o tópico "Data types" na documentação do Snowflake.
Updated 6 months ago