Caso 2: Migrando de Incremental para Incremental with Qualify | Documentação Dadosfera
Como adicionar deduplicação a uma pipeline incremental existente
Caso 2: Migrando de Incremental para Incremental with Qualify
Este guia demonstra como migrar uma pipeline incremental para o modo incremental_with_qualify, que adiciona deduplicação automática por primary key.
Problema: Pipelines incrementais capturam todas as versões de um registro, gerando duplicatas no destino.
Solução: Migrar para incremental_with_qualify, que mantém apenas a versão mais recente de cada registro.
Autenticação
import requests
import json
import os
from pprint import pprint
BASE_URL = "https://maestro.dadosfera.ai"
response = requests.post(
f"{BASE_URL}/auth/sign-in",
data=json.dumps({
"username": os.environ['DADOSFERA_USERNAME'],
"password": os.environ["DADOSFERA_PASSWORD"]
}),
headers={"Content-Type": "application/json"},
)
headers = {
"Authorization": response.json()['tokens']['accessToken'],
"Content-Type": "application/json"
}Passo 1: Identificar Pipeline e Job
Utilizamos a mesma pipeline criada no Caso 1.
PIPELINE_ID = "7b8b3399-b8c0-4fc5-9116-142cd9f4e7ae"
JOB_ID = "7b8b3399-b8c0-4fc5-9116-142cd9f4e7ae-0"response = requests.get(f"{BASE_URL}/platform/jobs/jdbc/{JOB_ID}", headers=headers)
job_config = response.json()
pprint(f"\nload_type atual: {job_config.get('source_config', {}).get('load_type')}")
pprint(f"primary_keys: {job_config.get('source_config', {}).get('primary_keys', 'NÃO DEFINIDAS')}")'load_type atual: incremental'
'primary_keys: None'Passo 2: Migrar Sync Mode
O endpoint POST /platform/jobs/jdbc/{jobId}/sync-mode realiza a migração com validação completa.
Parâmetros obrigatórios:
target_load_type: novo modo de sincronizaçãoprimary_keys: colunas que identificam unicamente cada registroincremental_column_nameeincremental_column_type: coluna de controle incremental
payload = {
"target_load_type": "incremental_with_qualify",
"incremental_column_name": "updated_at",
"incremental_column_type": "timestamp",
"primary_keys": ["id"]
}
response = requests.post(
f"{BASE_URL}/platform/jobs/jdbc/{JOB_ID}/sync-mode",
headers=headers,
json=payload
)
pprint(response.json()){
"message": "Successfully migrated sync mode to incremental_with_qualify",
"migration_details": {
"state_action": "preserve",
"target_load_type": "incremental_with_qualify",
"warnings": []
},
"status": "success"
}Passo 3: Verificar Alteração
O state_action: "preserve" indica que o estado incremental foi mantido — a próxima execução continua de onde parou.
response = requests.get(f"{BASE_URL}/platform/jobs/jdbc/{JOB_ID}", headers=headers)
job_config = response.json()
print(f"load_type: {job_config.get('source_config', {}).get('load_type')}")
print(f"primary_keys: {job_config.get('source_config', {}).get('primary_keys')}")load_type: incremental_with_qualify
primary_keys: ['id']Passo 4: Executar Pipeline
payload = {"pipeline_id": PIPELINE_ID}
response = requests.post(
f"{BASE_URL}/platform/pipeline/execute",
headers=headers,
json=payload
)
pprint(response.json())Resultado
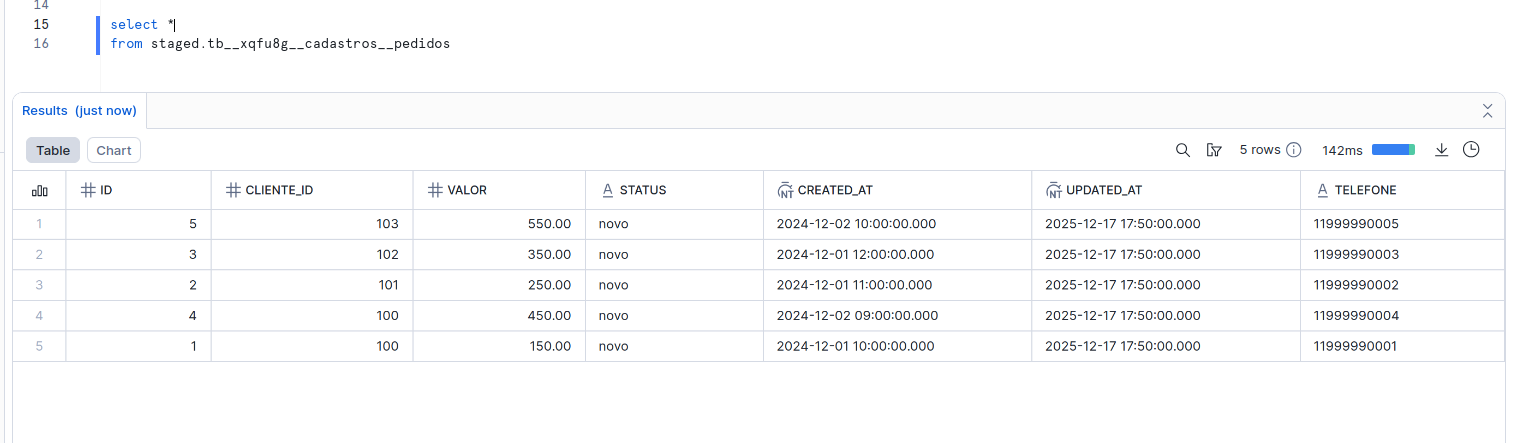
Com incremental_with_qualify, uma nova tabela é criada no schema STAGED contendo apenas a versão mais recente de cada registro. Tanto o schema como as tabelas são customizáveis pela API.
Resultados:
- IDs deduplicados (apenas 1 registro por
id) - Nova coluna
telefonepresente nos dados
Updated 6 months ago