Caso 1: Adicionando Coluna em Pipeline Incremental | Documentação Dadosfera
Como adicionar uma nova coluna e fazer backfill dos dados históricos
Caso 1: Adicionando Coluna em Pipeline Incremental
Este guia demonstra como adicionar uma nova coluna a uma pipeline incremental existente e realizar o backfill dos dados históricos.
Pré-requisito: Veja o notebook 00-setup-e-helpers.ipynb para entender como obter o job_id.
Autenticação
import requests
import os
import json
from pprint import pprint
BASE_URL = "https://maestro.dadosfera.ai"
response = requests.post(
f"{BASE_URL}/auth/sign-in",
data=json.dumps({
"username": os.environ['DADOSFERA_USERNAME'],
"password": os.environ["DADOSFERA_PASSWORD"]
}),
headers={"Content-Type": "application/json"},
)
headers = {
"Authorization": response.json()['tokens']['accessToken'],
"Content-Type": "application/json"
}Passo 1: Criar a pipeline de teste
Para este exemplo, criamos uma pipeline que sincroniza a tabela pedidos do MySQL.
import uuid
uuid.uuid4()payload = {
"id": "7b8b3399-b8c0-4fc5-9116-142cd9f4e7ae",
"name": "Orders",
"cron": "@once",
"description": "tabela pedidos",
"jobs": [
{
"input": {
"connector": "jdbc",
"plugin": "mysql",
"table_schema": "cadastros",
"table_name": "pedidos",
"load_type": "incremental",
"incremental_column_name": "updated_at",
"incremental_column_type": "timestamp",
"column_include_list": ["id","cliente_id","valor","status","created_at","updated_at"],
"auth_parameters": {
"auth_type": "connection_manager",
"config_id": "1763991009206_kvpd3364_mysql-1.0.0"
}
},
"transformations": [],
"output": {
"plugin": "dadosfera_snowflake"
}
}
]
}
response = requests.post(f"{BASE_URL}/platform/pipeline", headers=headers, data=json.dumps(payload))response = requests.get(f"{BASE_URL}/platform/pipeline/7b8b3399-b8c0-4fc5-9116-142cd9f4e7ae/pipeline_run", headers=headers)
response.json()[{
"last_status": "SUCCESS",
"pipeline_run_id": "cbab0131966a40809491555a8f23e272",
"updated_at": "2025-12-17T20:41:25.401858+00:00",
"pipeline_id": "7b8b3399_b8c0_4fc5_9116_142cd9f4e7ae",
"id": 2246,
"created_at": "2025-12-17T20:37:54.422460+00:00"
}]Passo 2: Consultar Job JDBC
JOB_ID = "7b8b3399-b8c0-4fc5-9116-142cd9f4e7ae-0"response = requests.get(f"{BASE_URL}/platform/jobs/jdbc/{JOB_ID}", headers=headers)
job_config = response.json()
pprint(job_config)
print("\nColunas atuais:")
print(job_config.get("source_config", {}).get("column_include_list", [])){
"cron": "@once",
"customer_id": "dadosfera",
"description": "tabela pedidos",
"id": "7b8b3399_b8c0_4fc5_9116_142cd9f4e7ae",
"job_name": "cadastros_pedidos",
"name": "Orders",
"output_config": {
"plugin": "dadosfera_snowflake",
"table_name": "tb__xqfu8g__cadastros__pedidos"
},
"source_config": {
"column_include_list": ["id", "cliente_id", "valor", "status", "created_at", "updated_at"],
"connector": "jdbc",
"incremental_column_name": "updated_at",
"incremental_column_type": "timestamp",
"load_type": "incremental",
"plugin": "mysql",
"table_name": "pedidos",
"table_schema": "cadastros"
}
}Colunas atuais:
['id', 'cliente_id', 'valor', 'status', 'created_at', 'updated_at']Resultado da primeira execução
A pipeline sincronizou os 5 registros iniciais da tabela pedidos.
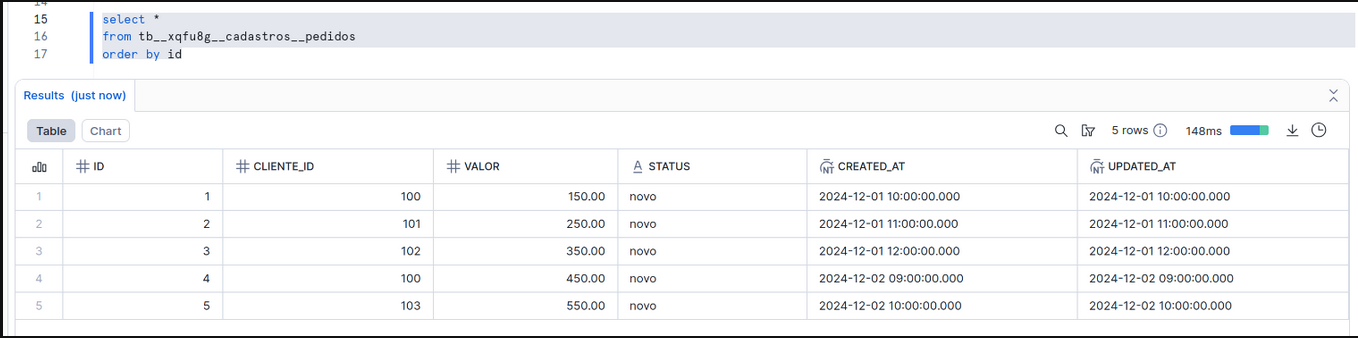
Passo 3: Adicionar Nova Coluna
O time de desenvolvimento adicionou uma nova coluna telefone na tabela de origem:
ALTER TABLE cadastros.pedidos ADD COLUMN telefone VARCHAR(20) DEFAULT NULL;
UPDATE cadastros.pedidos SET telefone = '11999990001', updated_at = '2025-12-17 16:50:00' WHERE id = 1;
UPDATE cadastros.pedidos SET telefone = '11999990002', updated_at = '2025-12-17 16:50:00' WHERE id = 2;
UPDATE cadastros.pedidos SET telefone = '11999990003', updated_at = '2025-12-17 16:50:00' WHERE id = 3;
UPDATE cadastros.pedidos SET telefone = '11999990004', updated_at = '2025-12-17 16:50:00' WHERE id = 4;
UPDATE cadastros.pedidos SET telefone = '11999990005', updated_at = '2025-12-17 16:50:00' WHERE id = 5;A pipeline executou novamente, mas sem a nova coluna configurada. Os dados foram replicados, porém a coluna telefone não aparece. Para corrigir, precisamos:
- Adicionar a coluna à configuração da pipeline
- Resetar o estado para re-extrair os dados com a nova coluna
Passo 4: Adicionar a nova coluna à pipeline
O endpoint PATCH /platform/jobs/{jobId}/input faz união das colunas — a nova coluna será adicionada às existentes.
NEW_COLUMN = "telefone"
payload = {
"column_include_list": [NEW_COLUMN]
}
response = requests.patch(
f"{BASE_URL}/platform/jobs/{JOB_ID}/input",
headers=headers,
json=payload
)
pprint(response.json()){
"detail": "Successfully updated input fields for job_id 7b8b3399_b8c0_4fc5_9116_142cd9f4e7ae_0",
"status": true,
"updated_fields": ["column_include_list", "info"]
}response = requests.get(f"{BASE_URL}/platform/jobs/jdbc/{JOB_ID}", headers=headers)
job_config = response.json()
print("Colunas após adição:")
print(job_config.get("source_config", {}).get("column_include_list", []))Colunas após adição:
['id', 'cliente_id', 'valor', 'status', 'created_at', 'updated_at', 'telefone']Passo 5: Resetar Estado Parcial (Backfill)
response = requests.post(
f"{BASE_URL}/platform/jobs/{JOB_ID}/reset-state",
data=json.dumps({"incremental_column_value": "2025-12-17 17:49:00"}),
headers=headers
)
pprint(response.json()){
"detail": "Successfully reset state for job_id 7b8b3399_b8c0_4fc5_9116_142cd9f4e7ae_0",
"incremental_column_value": "2025-12-17 17:49:00",
"state": {},
"status": true
}Passo 6: Limpar registros duplicados no destino
Antes de re-executar, no Snowflake, remova os registros que serão re-extraídos para evitar duplicação:
DELETE FROM public.tb__xqfu8g__cadastros__pedidos
WHERE updated_at >= '2025-12-17 17:50:00.000';Passo 7: Re-executar a pipeline
Resultado
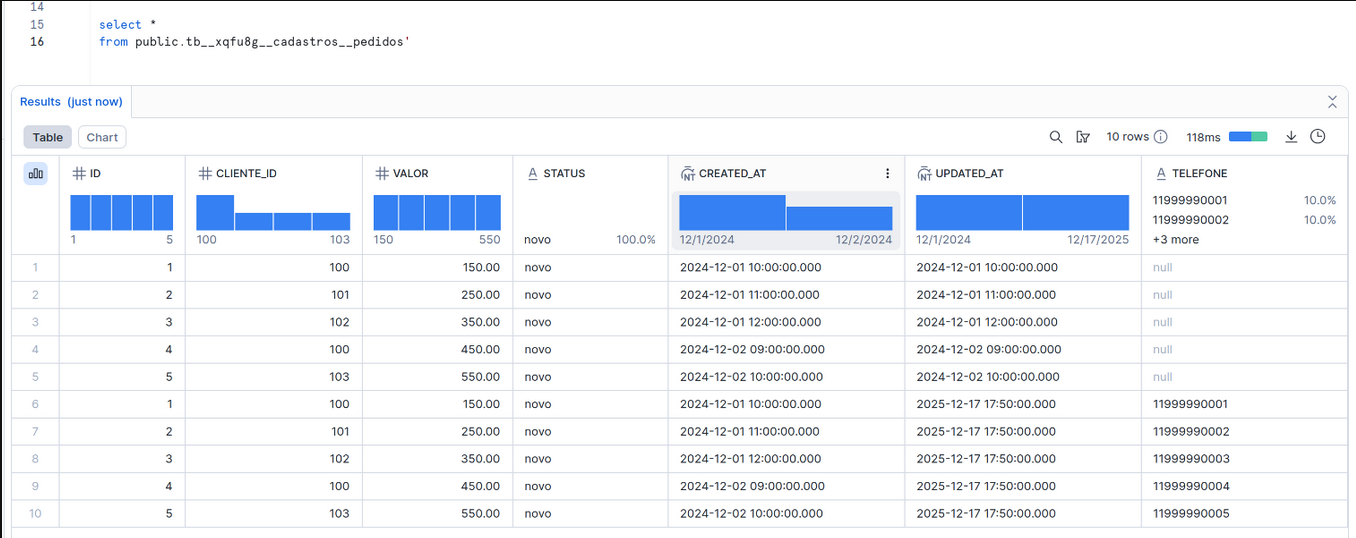
A coluna telefone agora está presente nos dados.
Note que existem registros duplicados (mesmo id com diferentes versões). Para resolver isso, veja o Caso 2: Migração para Incremental with Qualify.
Updated 6 months ago