Inteligência | Analisar | Documentação Dadosfera
Introdução
O que faz
Criação de notebooks e modelos de dados de forma visual e intuitiva, utilizando Python, R, Julia, JavaScript ou Bash, para a realização de análises descritivas e preditivas.
Assista uma curta demonstração do nosso Módulo de Inteligência e Análises Avançadas:
Funcionalidades
Estruturação e orquestração de pipelines de ciência de dados.
Construa interativamente seus pipelines de ciência de dados em nosso editor visual de pipeline. Versionado como um arquivo JSON.
Codifique scripts e notebooks
Execute scripts ou notebooks Jupyter como etapas em um pipeline. Python, R, Julia, JavaScript e Bash são suportados.
Jobs de execução
Parametrize seus pipelines e execute-os periodicamente em uma programação cron.
Environments
Instale facilmente pacotes. Construído em cima de imagens regulares de contêiner do Docker.
Abaixo, um vídeo curto com um tutorial técnico do Módulo de Inteligência e Análises Avançadas que aborda:
- Criação um novo projeto;
- Apresentação da interface da aba Pipelines e tutorial de como criá-las;
- Apresentação do menu de configurações;
- Apresentação da interface do menu Enviroments;
- Apresentação da interface do menu Jobs e como criar um notebook no Jupyterlab;
- Tutorial de como rodar um Data App e como criar um ativo de Dados com o Data App diretamente no catálogo da Dadosfera.
Limitações
Verifique se o plano contratado pela sua empresa possui acesso ao Módulo de Inteligência.
Este Módulo é parcialmente apartado dos demais módulos nativos da Dadosfera por possuir uma infra totalmente alocada para o seu funcionamento ocorrer de forma mais eficiente possível.
Este Módulo é oferecido atualmente apenas em Inglês.
Conceitos
Do ponto de vista de alto nível, todas as páginas do Módulo são apenas "visualizações" de arquivos no sistema de arquivos. De forma detalhada:
Projects
Fora as configurações globais e da autenticação, tudo no Módulo é encapsulado por Projetos. Você pode pensar em um Projeto como uma pasta em seu sistema de arquivos que contém um monte de Arquivos.
Files
Dentro de um Projeto é possível ter quantos arquivos sejam necessários, os quais são passíveis de serem executados. Podem ser elaborados com: Python, Notebooks e arquivos R.
Pipelines
Outro conceito importante na Dadosfera são os Pipelines. Um Pipeline pode ser construído conectando múltiplos passos , que determina a ordem de execução e estão conectados de forma a continuar trabalhando em dados resultantes. A descrição completa de um Pipeline é armazenada em um único arquivo JSON, isso significa que os Pipelines podem ser totalmente versionados, para que você possa controlar quaisquer mudanças feitas neles.
Environments
Por ser um módulo totalmente conteinerizado, todo o seu código precisa ser executado em um recipiente. Combinado com o fato de que o código pode depender de dependências adicionais (quem não usou uma biblioteca antes) o contêiner (a imagem subjacente para ser mais preciso) precisa ser configurado para suas necessidades. É possível personalizar totalmente suas imagens de contêiner usando um script de configuração, que criamos automaticamente para você. Isso é o que chamamos de Ambiente.
Jobs
Após criar o Pipeline, codificar os arquivos, configurar suas etapas e configurar os Environments, inevitavelmente o Pipeline deve ser executado. Isso pode ser feito por executando um Pipeline dentro do editor de pipeline ou por meio de Jobs. O primeiro permite teste fácil enquanto você está desenvolvendo seu Pipeline e o último (Jobs) permite que você execute seu Pipeline em produção em uma programação recorrente (por exemplo, diariamente). Veja aqui o tutorial completo de como agendar sua pipeline.
Atalhos do teclado (shortcuts)
| Key | Ação |
|---|---|
| Space + click + drag | Pan canvas * |
| Scroll up/down | Pan the canvas up/down * |
| Scroll left/right | Pan the canvas left/right * |
| Shift + scroll up/down | Pan the canvas left/right * |
| Shift + scroll left/right | Pan the canvas up/down * |
| Ctrl (or ⌘) + scroll up/down | Zoom in/out * |
| Ctrl + click | Select multiple steps |
| Ctrl + A | Select all steps * |
| Ctrl + Enter | Run selected steps * |
| H | Center view and reset zoom |
| Escape | Deselect steps |
| Delete/Backspace | Delete selected step(s) |
| Double click a step | Open file in JupyterLab |
Configurações gerais
O Módulo é configurado através das Settings. Algumas configurações exigem que o Módulo seja reiniciado para que as alterações tenham efeito. Por exemplo:
{
"AUTH_ENABLED": false,
"MAX_BUILDS_PARALLELISM": 1,
"MAX_INTERACTIVE_RUNS_PARALLELISM": 4,
"MAX_JOB_RUNS_PARALLELISM": 4,
"TELEMETRY_DISABLED": false,
"TELEMETRY_UUID": "69b40767-e315-4953-8a2b-355833e344b8"
}- AUTH_ENABLED: Habilita a autenticação. Quando habilitada, a Dadosfera exigirá um login. Crie contas de usuário através das Configurações > Gerenciar Usuários. A Dadosfera ainda não suporta sessões de usuário individuais, o que significa que não há granularidade ou segurança entre usuários. (Booleano: true ou false)
Por padrão a autenticação é habilitada. Não recomendamos retirá-la, deixando o módulo exposto para acesso de qualquer usuário, sem a realização de login.
- MAX_BUILDS_PARALLELISM: Controla o número total de {term}ambientes e builds de imagem JupyterLab que podem ser executados em paralelo. (Inteiro entre: [1, 25])
- MAX_INTERACTIVE_RUNS_PARALLELISM: Controla o número de {term}execuções interativas <execução interativa (de pipeline)> que podem ser executadas em paralelo para diferentes pipelines em um determinado momento. Por exemplo, se isso for definido como 2, então apenas 2 pipelines diferentes podem ter execuções interativas ao mesmo tempo. Isso é útil quando vários usuários estão usando a Dadosfera. (Inteiro entre: [1, 25])
- MAX_JOB_RUNS_PARALLELISM: Controla o número de execuções de job que podem ser executadas em paralelo em todos os jobs. Por exemplo, se isso for definido como 3, apenas 3 execuções de pipeline podem ser executadas em paralelo. (Inteiro entre: [1, 25])
- TELEMETRY_DISABLED: Desativa a telemetria. (Booleano: true ou false)
- TELEMETRY_UUID: UUID para rastrear o uso em sessões de usuário.
Acesso ao Módulo
Por possuir uma infra totalmente apartada dos demais módulos nativos da Dadosfera, a e Acesso e a Gestão do Módulo de Processamento não está hoje integrada com a gestão de acessos da Dadosfera. Veja abaixo como gerenciar os acessos a este módulo:
Recomendamos fortemente a utilização de login individual para acesso na Dadosfera, dessa forma é possível realizar um melhor controle de permissão e auditoria.
A Dadosfera não possui limitação quanto ao número de usuários por cliente.
Primeiro Acesso
O primeiro acesso é fornecido ao Super Admin da organização pelo suporte da Dadosfera assim que o Módulo é adquirido, por email. Após esse primeiro acesso, a gestão de acessos fica por conta da própria organização.
Gestão de Acessos
Criar usuários
- Acesse o seu ambiente.
- Na página inicial, no topo superior direito, vá em 'Settings':

- No menu que se abrirá à esquerda, acesse 'User management':
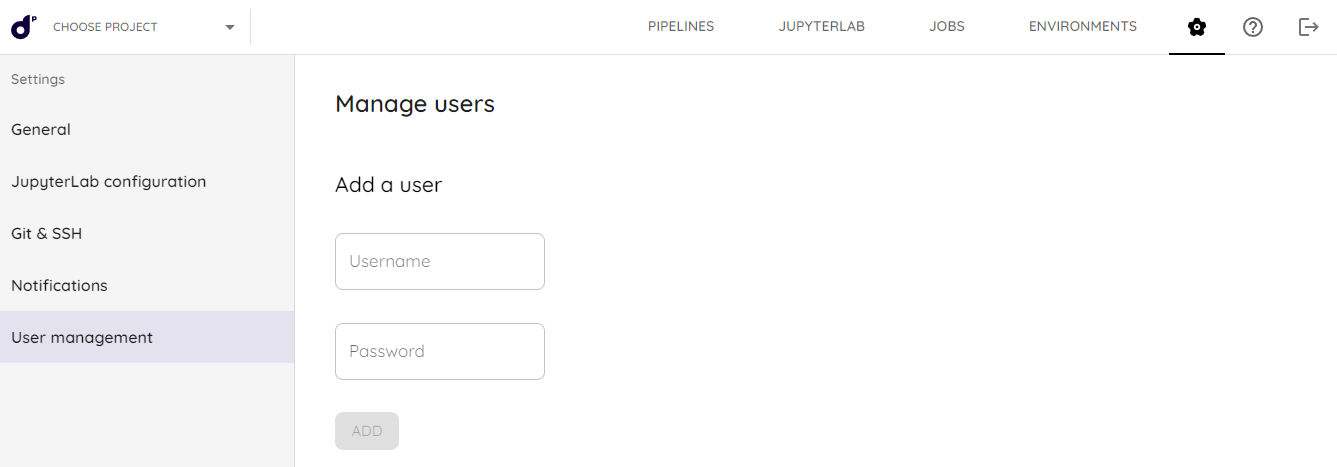
- Defina o Username (pode ser o email) e o Password (senha) e clique em 'Add'
- Pronto! Basta compartilhar, de forma segura, as credenciais.
O primeiro usuário de acesso ao módulo é disponibilizado pelo suporte da Dadosfera, os demais acessos ficam à cargo deste usuário.
Deletar usuários
- Acesse a tela de 'User management'.
- Encontre o usuário na lista 'Delete users' e aperte em 'DELETE'.
Projetos de Exemplo
É possível acessar Project Examples através do seguinte repositório no Github: intelligence-module-examples.
No repositório você encontrará scripts criados em casos de uso de modelagem de dados utilizando o módulo. Os datasets originais utilizados na modelagem não são disponibilizados. Portanto, os scripts servem apenas de exemplo.
Em breve esses projetos estarão na própria interface do módulo.
Tutoriais
Criando um Projeto
Você pode começar um projeto de 3 formas:
- Criando um novo projeto.
- Importando um projeto existente.
- Importando exemplos curados pela Dadosfera ou pela comunidade.
Criando e configurando Pipelines
Os pipelines são uma ferramenta interativa para criar e experimentar seu fluxo de trabalho de dados no Módulo. Um Pipeline é composto de etapas e conexões:
- As etapas são arquivos executáveis executados em seus próprios ambientes isolados.
- As conexões vinculam etapas para definir como os dados fluem (consulte passagem de dados) e a ordem de execução da etapa.
Os pipelines são editados visualmente e armazenados no formato JSON no arquivo de definição do pipeline. Isso permite que as alterações do Pipeline (por exemplo, adicionar uma etapa) sejam versionadas.
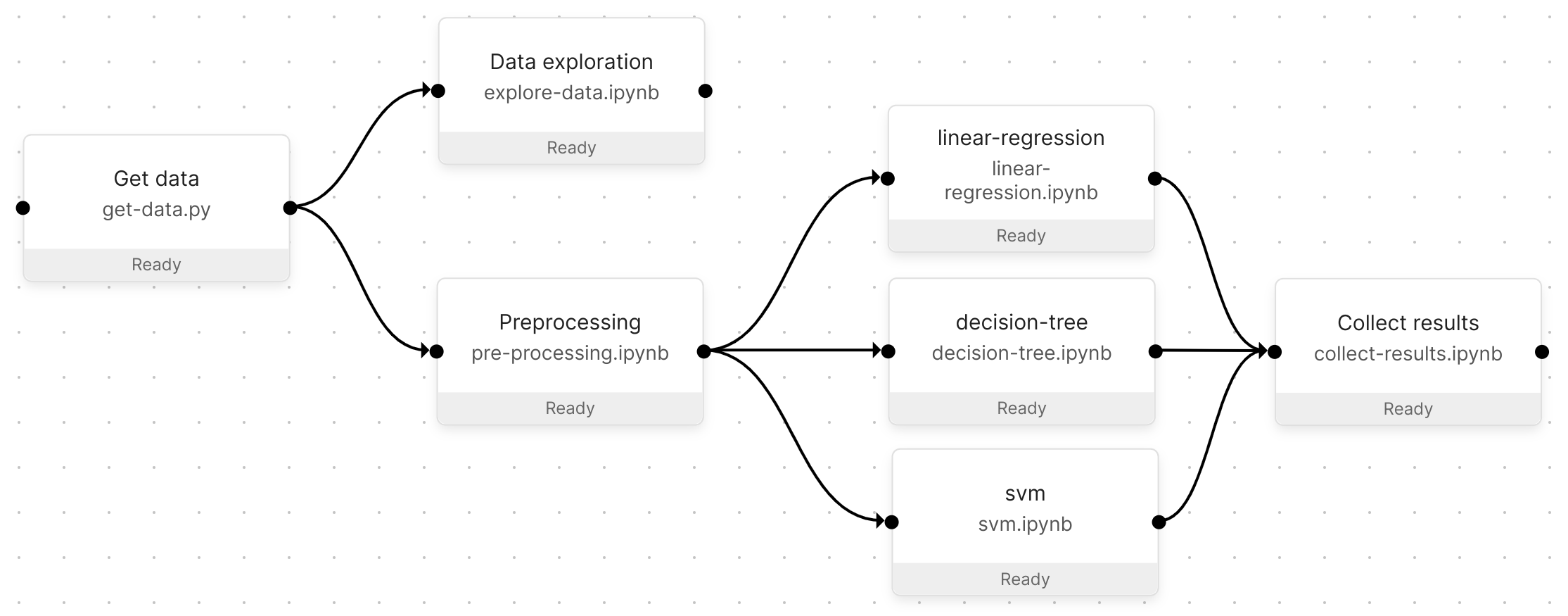
Exemplo de pipeline
Parametrizando Pipelines
Os pipelines usam parâmetros como entrada (por exemplo, a URL de conexão da fonte de dados) para variar seu comportamento. Os trabalhos podem usar parâmetros diferentes para iterar em várias execuções do mesmo pipeline. Os parâmetros podem ser definidos no editor de pipeline visual.
Você pode definir os parâmetros do Pipeline em dois níveis:
- Pipelines: os parâmetros e seus valores estarão disponíveis em todas as etapas do Pipeline.
- Etapas do pipeline: Os parâmetros só estarão disponíveis quando forem definidos.
Editando parâmetros de pipeline
- Abra um Pipeline através da opção Pipelines no painel de menu esquerdo.
- Clique em CONFIGURAÇÕES no canto superior direito.
- No topo, você encontrará a seção de parâmetros do Pipeline.
- Insira algum JSON como
{"my-param": <param-value>}. - Certifique-se de salvar na parte inferior da tela.
Editando os parâmetros da etapa do pipeline
- Abra um Pipeline através da opção Pipelines na barra de navegação.
- Clique em uma etapa do pipeline para abrir suas propriedades.
- Na parte inferior, você encontrará a seção Parâmetros.
- Insira algum JSON como
{"my-param": <param-value>}.
Criando Environments
Os ambientes definem as condições em que os passos do pipeline executam scripts e kernels. Os ambientes são:
- Escolhidos no painel de propriedades do passo do pipeline no }editor de pipelines.
- Configuráveis através do script de configuração (na página de ambientes) para instalar pacotes adicionais.
- Versionados e pertencentes a um único projects.
Escolhendo uma linguagem de programação na Dadosfera
Um ambiente usa apenas uma linguagem de programação para evitar a sobrecarga da imagem do contêiner com muitas dependências. O Módulo tem suporte integrado para ambientes com as linguagens:
- Python
- R
- JavaScript
- Julia
Cada ambiente suporta scripts Bash para invocar qualquer outra linguagem indiretamente. Por exemplo: Java, Scala, Go ou C++.
Para criar o ambiente:
- Vá para a página Environments.
- Crie um novo Ambiente.
- Escolha um nome de Ambiente.
- Escolha uma imagem base.
- Escolha uma das linguagens suportadas.
- Adicione comandos de instalação para pacotes adicionais no script de configuração do Ambiente.
- Pressione o botão Build.
Agendando jobs para sua pipeline
Após criar o Pipeline, codificar os arquivos, configurar suas etapas e configurar os Environments, inevitavelmente o Pipeline deve ser executado. Isso pode ser feito por executando um Pipeline dentro do editor de pipeline ou por meio de Jobs. O primeiro permite teste fácil enquanto você está desenvolvendo seu Pipeline e o último (Jobs) permite que você execute seu Pipeline em produção em uma programação recorrente (por exemplo, diariamente). Veja abaixo o tutorial completo de como agendar sua pipeline.
Pré-requisitos
- Acesso ao Módulo de Tranformação.
- Connection_parameters da conta Snowflake.
Passo a passo:
O procedimento para executar um trabalho parametrizado é muito semelhante à execução de um trabalho sem nenhum parâmetro. Depois de seguir qualquer um dos procedimentos acima para parametrizar sua pipeline:
- Certifique-se de ter definido os parâmetros básicos da Pipeline.
- Clique em Jobs no painel de menu à esquerda.
- Clique no botão + new job para configurar seu trabalho.
- Escolha um Job name e a Pipeline que deseja executar o job.
- Seu conjunto padrão de parâmetros é pré-carregado. Ao clicar nos valores, um editor JSON é aberto, permitindo que você adicione valores adicionais que deseja que a Pipeline execute.
- Se você quiser agendar o trabalho para ser executado em um horário específico, dê uma olhada em Scheduling.
- Pressione Run job.
Tour guiado:
Importar a lib Dadosfera versão Snowpark
Biblioteca intuitiva para consultar e processar dados em escala no Snowflake. Atualmente, o Snowflake fornece bibliotecas Snowpark para três idiomas: Java, Python e Scala, complementares à interface SQL original do Snowflake.
Para importar a lib no Módulo de Transformação da Dadosfera, siga os passos abaixo:
1 - Criar uma pasta chamada dadosfera na raiz do projeto.
2 - Criar um arquivo chamado snowflake.py dentro da pasta dadosfera.
3 - Colocar esse conteúdo no arquivo:
import os
import pandas as pd
from snowflake.snowpark import functions as F
import orchest as utils
connection_parameters = {
"user": os.environ.get('SNOWFLAKE_USER'),
"password": os.environ.get('SNOWFLAKE_PASSWORD'),
"account": os.environ.get('SNOWFLAKE_ACCOUNT'),
"warehouse": 'COMPUTE_WH',
"database": os.environ.get('SNOWFLAKE_DATABASE'),
"schema": 'PUBLIC',
}
def create_pandas_df(snowpark_df):
rows = snowpark_df.collect()
data = []
for row in rows:
data.append(row.as_dict())
df = pd.DataFrame(data)
for column in df.columns:
df = df.rename({column: column.lower()}, axis=1)
return df
def remove_quotes_from_columns(df, columns):
clean_function = [
F.trim(F.replace(column, '"', ''))
for column in columns
]
df = df.with_columns(columns, clean_function)
return df
def empty_string_as_null(df, columns):
empty_string_as_null_columns = [
f"nullif({column}, '') as {column}"
for column in columns
]
df = df.selectExpr(*empty_string_as_null_columns)
return dfCaso você ainda não possua os connection_parameters da sua conta Snowflake, solicite ao [email protected].
4 - As variáveis podem ser setadas a nível de pipeline da seguinte forma:
Clica nos ... -> Pipeline Settings -> Environment Variables
5 - Importante dar o start novamente no kernel do notebook para que as novas variáveis sejam utilizadas.
6 - Restaure a sessão.
Pronto! A lib está pronta para ser utilizada.
Configuração de notificações
Você pode receber notificações de webhook quando eventos específicos ocorrem no Módulo. Por exemplo, quando uma tarefa falha. Sempre que um evento é acionado, a Dadosfera enviará uma solicitação HTTP para o seu endpoint desejado com um payload de informações. Por exemplo:
{
"delivered_for": {
"name": "Test webhook",
"verify_ssl": false,
"content_type": "application/json",
"uuid": "a1edb89c-1cfb-4086-8f75-ab073612c5bf",
"type": "webhook"
},
"event": {
"type": "ping",
"uuid": "08bd2a31-9b17-4d1b-83ba-b4538a970dee",
"timestamp": "2022-06-02 16:12:25.242592+00:00"
}
}Para criar um webhook, acesse "Configurações de notificação". O diálogo do webhook solicitará o seguinte:
- URL do webhook: onde a Dadosfera envia as solicitações HTTP. Ative os webhooks de entrada no canal desejado (por exemplo: Slack) e verifique a conexão com o botão "Testar".
- Tipo de conteúdo: application/json (padrão) ou application/x-www-form-urlencoded.
- Nome do webhook (opcional): um nome personalizado para seu webhook. Isso é útil ao criar vários webhooks com URLs semelhantes.
- Segredo (opcional): uma string secreta que você pode usar para verificar a origem da solicitação (consulte {ref}abaixo <secure_webhook>).
Verificando o webhook
O seguinte código de exemplo verifica se a assinatura do payload é a mesma que a esperada pelo segredo do webhook armazenado:
import hashlib
import hmac
import os
def verify_signature(payload, request_headers):
"""
Verifica se a assinatura do payload é a mesma
que a esperada pelo segredo do webhook armazenado.
"""
if not isinstance(body, bytes):
body = body.encode("utf-8")
digest = hmac.new(
os.environ["WEBHOOK_SECRET"].encode("utf-8"),
body,
hashlib.sha256
)Compartilhando código entre diferentes projetos
O módulo de inteligência contém um diretório global onde pode ser adicionado arquivos de códigos para serem utilizados em diferentes projetos. Esse diretório é o /data
Para utilizá-lo, basta seguir os seguintes passos:
1. Adicione o arquivo contendo o código que você quer compartilhar dentro do diretório /data
/data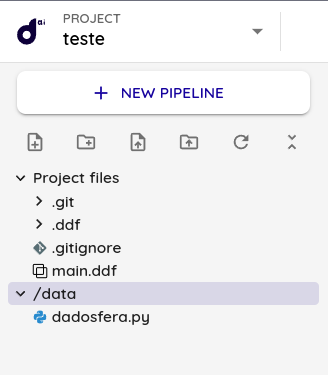
2. Adicione o seguinte script aos environments onde deseja utlizar as funções do arquivo e execute o build
echo 'export PYTHONPATH="${PYTHONPATH}:/data"' >> /home/jovyan/.orchestrc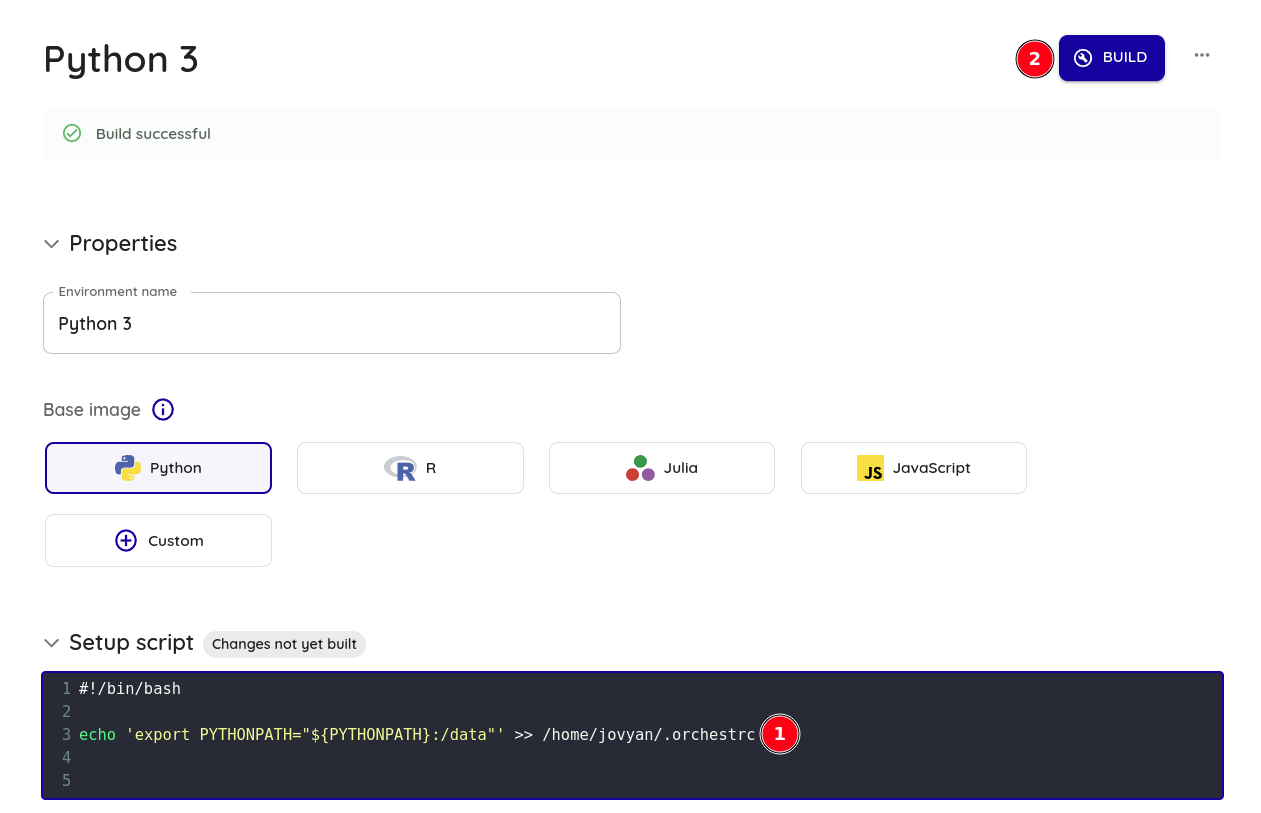
3. Reinicie a sessão da sua pipeline
4. Pronto! Basta importar as funções do arquivo como se fosse uma biblioteca
O nome utilizado para importação é o mesmo nome do arquivo. Certifique-se de dar um nome único para que não ocorra conflitos com outras bibliotecas
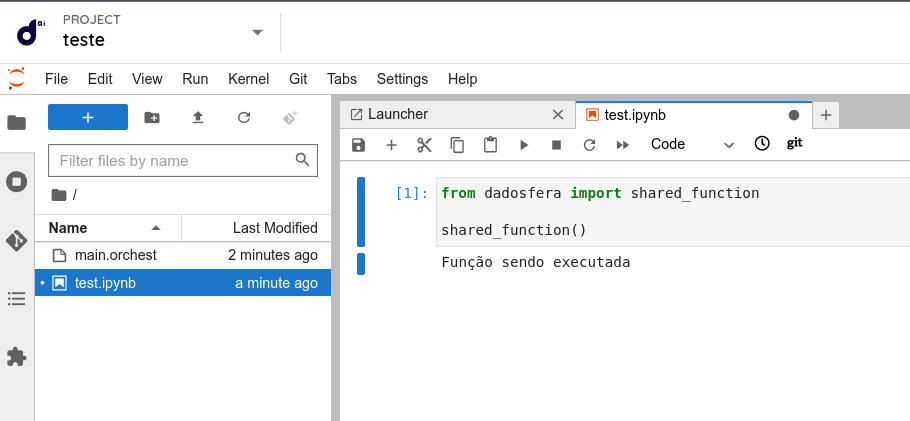
ImportanteOs arquivos em
/datanão podem ser editados. Caso deseje alterar algo no arquivo mova-o para o seu projeto, faça as alterações e insira-o novamente no/data
Updated 6 months ago