Introdução | Processar | Documentação Dadosfera
O que é o Módulo de Processamento?
Crie fluxos de Transformação de Dados, em Python, R ou Julia dentro da Dadosfera. Todo o poder do Snowflake, Python, com as mesmas chamadas que PySpark e Pandas utiliza.
Limitações
Verifique se o plano contratado pela sua empresa possui acesso ao Módulo de Processamento.
Este Módulo é parcialmente apartado dos demais módulos nativos da Dadosfera por possuir uma infra totalmente alocada para o seu funcionamento ocorrer de forma mais eficiente possível.
Este Módulo é oferecido atualmente apenas em Inglês.
Conceitos
Do ponto de vista de alto nível, todas as páginas do Módulo são apenas "visualizações" de arquivos no sistema de arquivos. De forma detalhada:
Projects
Fora as configurações globais e da autenticação, tudo no Módulo é encapsulado por Projetos. Você pode pensar em um Projeto como uma pasta em seu sistema de arquivos que contém um monte de Arquivos.
Files
No projeto, é possível adicionar quantos arquivos forem necessários para garantir o bom funcionamento e desempenho do sistema. O ambiente oferece suporte para arquivos em diversas linguagens, como Python, R, Julia, além de Notebooks. Todos esses arquivos podem ser interconectados, permitindo a criação de fluxos de trabalho integrados e contínuos entre diferentes linguagens e formatos.
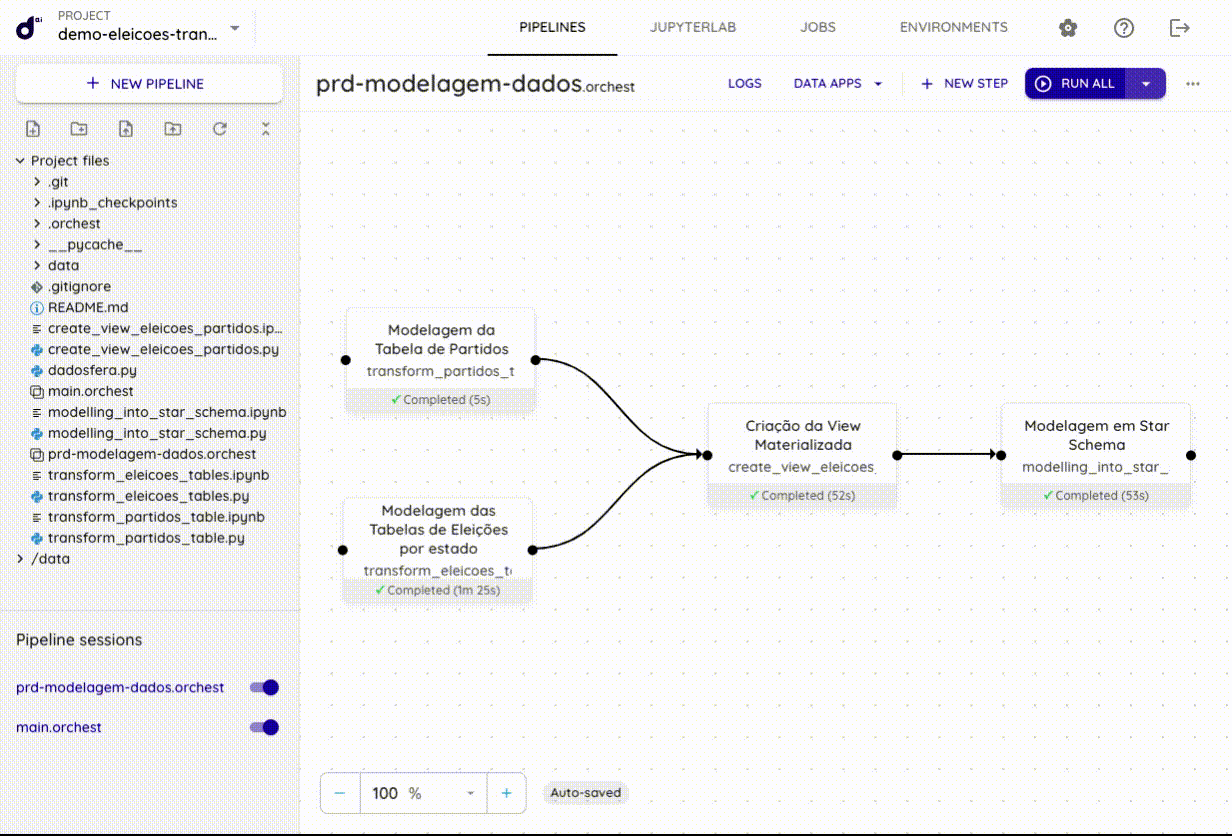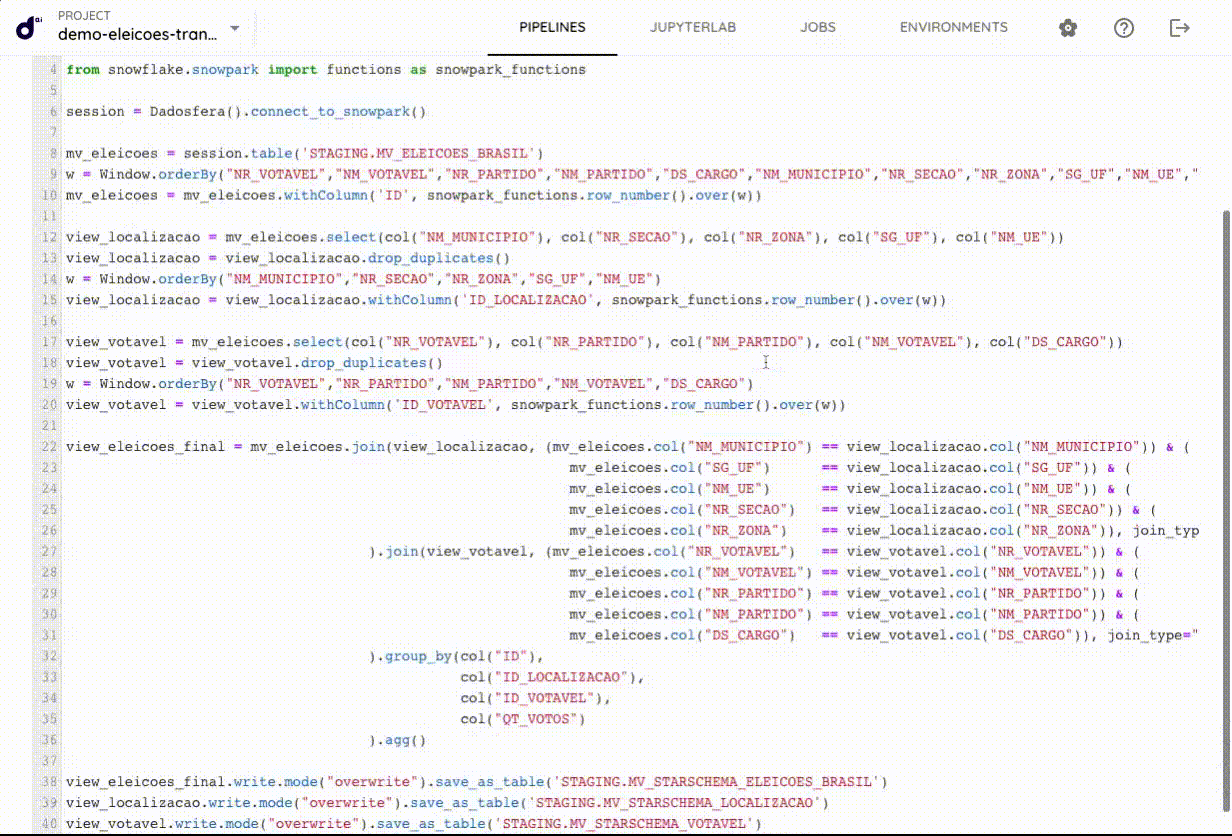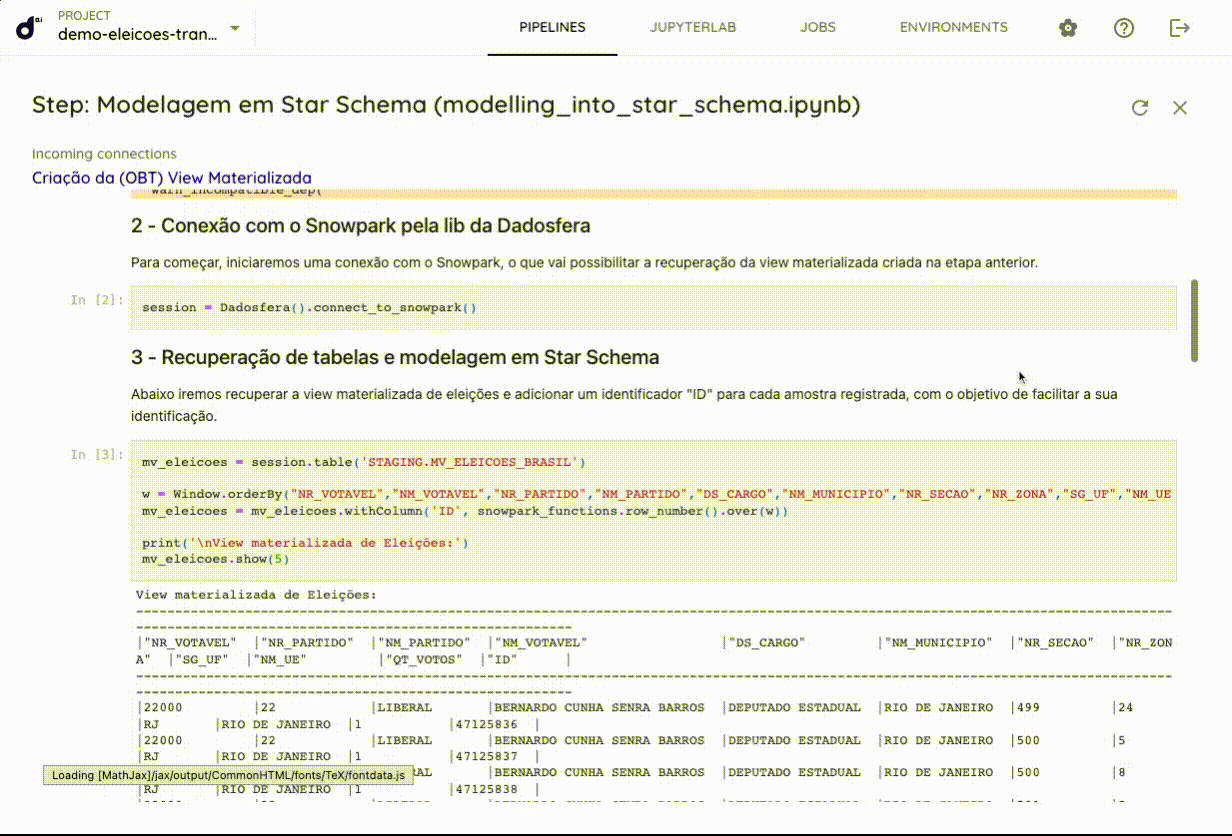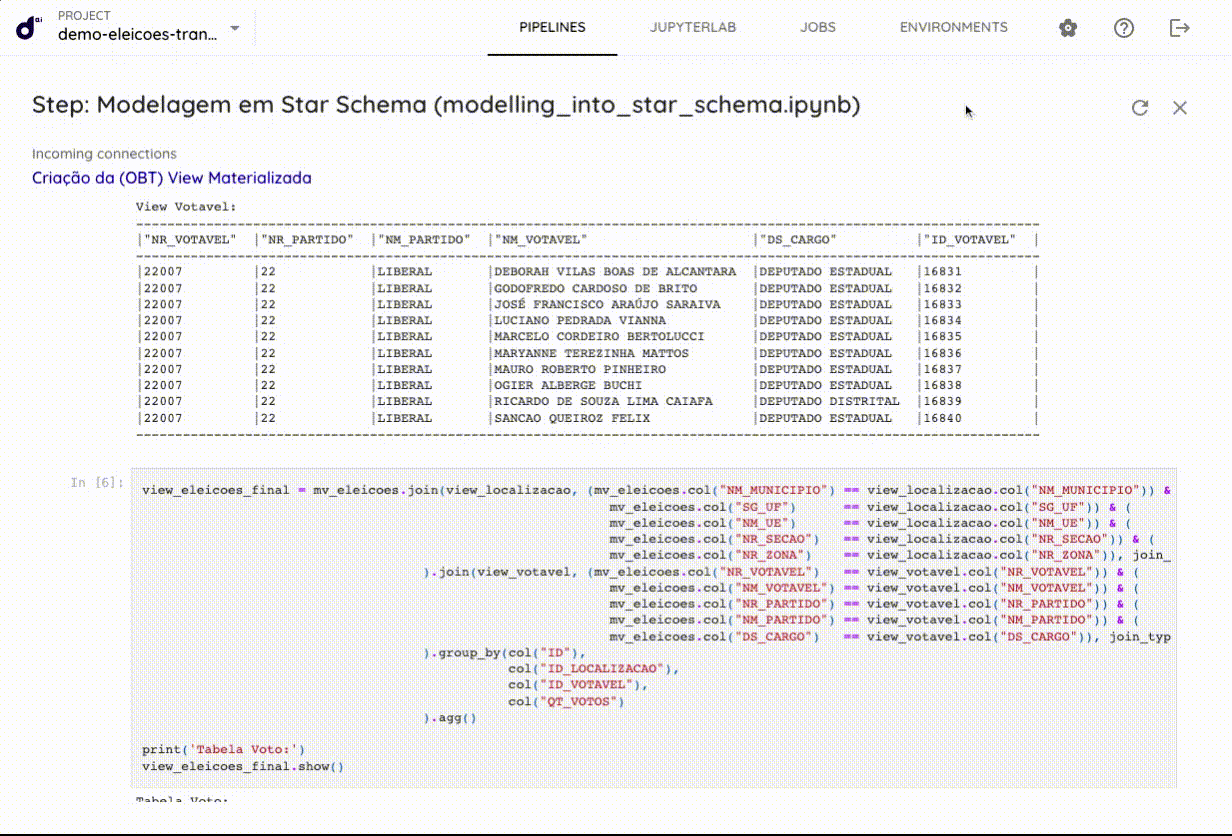
Pipelines
Outro conceito importante na Dadosfera são os Pipelines. Um Pipeline pode ser construído conectando múltiplos passos , que determina a ordem de execução e estão conectados de forma a continuar trabalhando em dados resultantes. A descrição completa de um Pipeline é armazenada em um único arquivo JSON, isso significa que os Pipelines podem ser totalmente versionados, para que você possa controlar quaisquer mudanças feitas neles.
Environments
Por ser um módulo totalmente conteinerizado, todo o seu código precisa ser executado em um recipiente. Combinado com o fato de que o código pode depender de dependências adicionais (quem não usou uma biblioteca antes) o contêiner (a imagem subjacente para ser mais preciso) precisa ser configurado para suas necessidades. É possível personalizar totalmente suas imagens de contêiner usando um script de configuração, que criamos automaticamente para você. Isso é o que chamamos de Ambiente.
Jobs
Após criar o Pipeline, codificar os arquivos, configurar suas etapas e configurar os Environments, inevitavelmente o Pipeline deve ser executado. Isso pode ser feito de duas maneiras: executando um pipeline dentro do editor de pipeline ou por meio de Jobs. A primeira opção permite um teste fácil enquanto você está desenvolvendo seu Pipeline e o último (Jobs) permite que você execute seu Pipeline que está em produção em uma programação recorrente (por exemplo, diariamente). Veja aqui o tutorial completo de como agendar sua pipeline.
Atalhos do teclado (shortcuts)
| Key | Ação |
|---|---|
| Space + click + drag | Pan canvas * |
| Scroll up/down | Pan the canvas up/down * |
| Scroll left/right | Pan the canvas left/right * |
| Shift + scroll up/down | Pan the canvas left/right * |
| Shift + scroll left/right | Pan the canvas up/down * |
| Ctrl (or ⌘) + scroll up/down | Zoom in/out * |
| Ctrl + click | Select multiple steps |
| Ctrl + A | Select all steps * |
| Ctrl + Enter | Run selected steps * |
| H | Center view and reset zoom |
| Escape | Deselect steps |
| Delete/Backspace | Delete selected step(s) |
| Double click a step | Open file in JupyterLab |
Configurações gerais
O Módulo é configurado através das Settings. Algumas configurações exigem que o Módulo seja reiniciado para que as alterações tenham efeito. Por exemplo:
{
"AUTH_ENABLED": false,
"MAX_BUILDS_PARALLELISM": 1,
"MAX_INTERACTIVE_RUNS_PARALLELISM": 4,
"MAX_JOB_RUNS_PARALLELISM": 4,
"TELEMETRY_DISABLED": false,
"TELEMETRY_UUID": "69b40767-e315-4953-8a2b-355833e344b8"
}- AUTH_ENABLED: Habilita a autenticação. Quando habilitada, a Dadosfera exigirá um login. Crie contas de usuário através das Configurações > Gerenciar Usuários. A Dadosfera ainda não suporta sessões de usuário individuais, o que significa que não há granularidade ou segurança entre usuários. (Booleano: true ou false)
Por padrão a autenticação é habilitada. Não recomendamos retirá-la, deixando o módulo exposto para acesso de qualquer usuário, sem a realização de login.
- MAX_BUILDS_PARALLELISM: Controla o número total de {term}ambientes e builds de imagem JupyterLab que podem ser executados em paralelo. (Inteiro entre: [1, 25])
- MAX_INTERACTIVE_RUNS_PARALLELISM: Controla o número de {term}execuções interativas <execução interativa (de pipeline)> que podem ser executadas em paralelo para diferentes pipelines em um determinado momento. Por exemplo, se isso for definido como 2, então apenas 2 pipelines diferentes podem ter execuções interativas ao mesmo tempo. Isso é útil quando vários usuários estão usando a Dadosfera. (Inteiro entre: [1, 25])
- MAX_JOB_RUNS_PARALLELISM: Controla o número de execuções de job que podem ser executadas em paralelo em todos os jobs. Por exemplo, se isso for definido como 3, apenas 3 execuções de pipeline podem ser executadas em paralelo. (Inteiro entre: [1, 25])
- TELEMETRY_DISABLED: Desativa a telemetria. (Booleano: true ou false)
- TELEMETRY_UUID: UUID para rastrear o uso em sessões de usuário.
Updated 6 months ago