Coletando o dado
Coletando o dado
A primeira etapa é inserir dados na Dadosfera. Isto pode ser feito de duas formas:
- Criação de uma pipeline de coleta, na qual há uma fonte de dados para realizar a extração dos dados, para carregamento recorrente na Dadosfera, por meio da definição de um agendamento.
- Importação manual de arquivos CSV, para dados que estão no seu dispositivo e são arquivos estáticos (não haverá mudança ou novos registros).
Para este guia, utilizaremos o dataset IBM HR Analytics Employee Attrition & Performance, conjunto de dados fictício criado por cientistas de dados da IBM a respeito dos fatores que levam o desgaste do funcionário, que está disponível livremente para análise, sob a licença Open Data Commons
a) Baixar arquivo
Baixe diretamente o arquivo neste link.
Não são aceitos arquivos zip. Por isso, ao baixar o dataset acima, lembre-se de extrair o arquivo CSV que se localiza dentro do arquivo zip.
b) Importar para a Dadosfera
- Vá em Coletar > Importar arquivos
-
Nesta tela, arraste o arquivo para dentro da sessão marcada na página, ou busque diretamente do seu computador, no diretório onde o dataset baixado foi salvo:

- Na etapa seguinte é possível editar o nome do arquivo importado. A descrição é um campo obrigatório, dessa forma, será possível compreender o contexto do arquivo posteriormente da melhor forma possível.
- Já nas configurações do arquivo, defina o tipo de codificação - o padrão brasileiro é o UTF-8, o separador dos caracteres do CSV e se ele possui cabeçalho.
c) Acompanhar importação
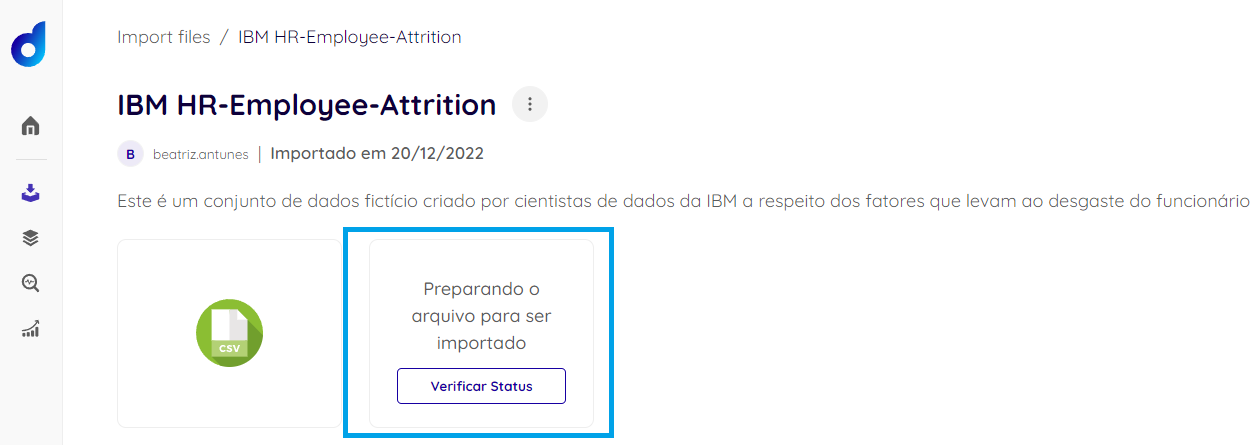
- Verifique o Status da extração do arquivo do seu dispositivo:
- Acompanhe a importação, ou seja, o carregamento do arquivo para a Dadosfera:
- Assim que a importação for concluída, será possível acessar uma prévia dos dados e acessar o dataset completo no catálogo, clicando neste card abaixo:
Updated 5 months ago