Collecting Data
Collecting Data
The first step is to insert data into Dadosfera. This can be done in two ways:
- Creation of a data collection pipeline, in which there is a data source to extract the data for recurring loading into Dadosfera, through the definition of a schedule.
- Manual file import of CSV files, for data that is on your device and are static files (there will be no changes or new records).
For this guide, we will use the dataset IBM HR Analytics Employee Attrition & Performance, a fictitious dataset created by IBM data scientists about the factors that lead to employee attrition, which is freely available for analysis under the Open Data Commons license
a) Download File
Download the file directly from this link.
Zip files are not accepted. Therefore, when downloading the above dataset, remember to extract the CSV file located inside the zip file.
b) Import to Dadosfera
- Go to Collect > Import files
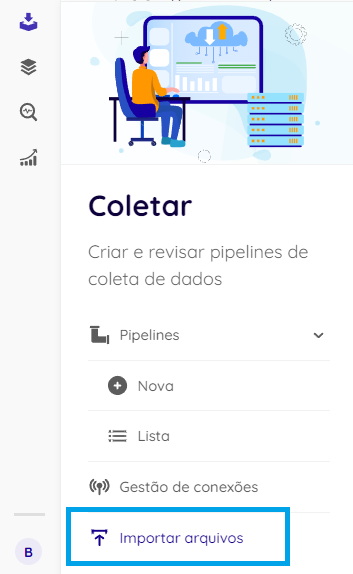
Center-aligned, 30% sizing, with border
-
On this screen, drag the file into the marked session on the page, or search directly from your computer, in the directory where the downloaded dataset was saved:
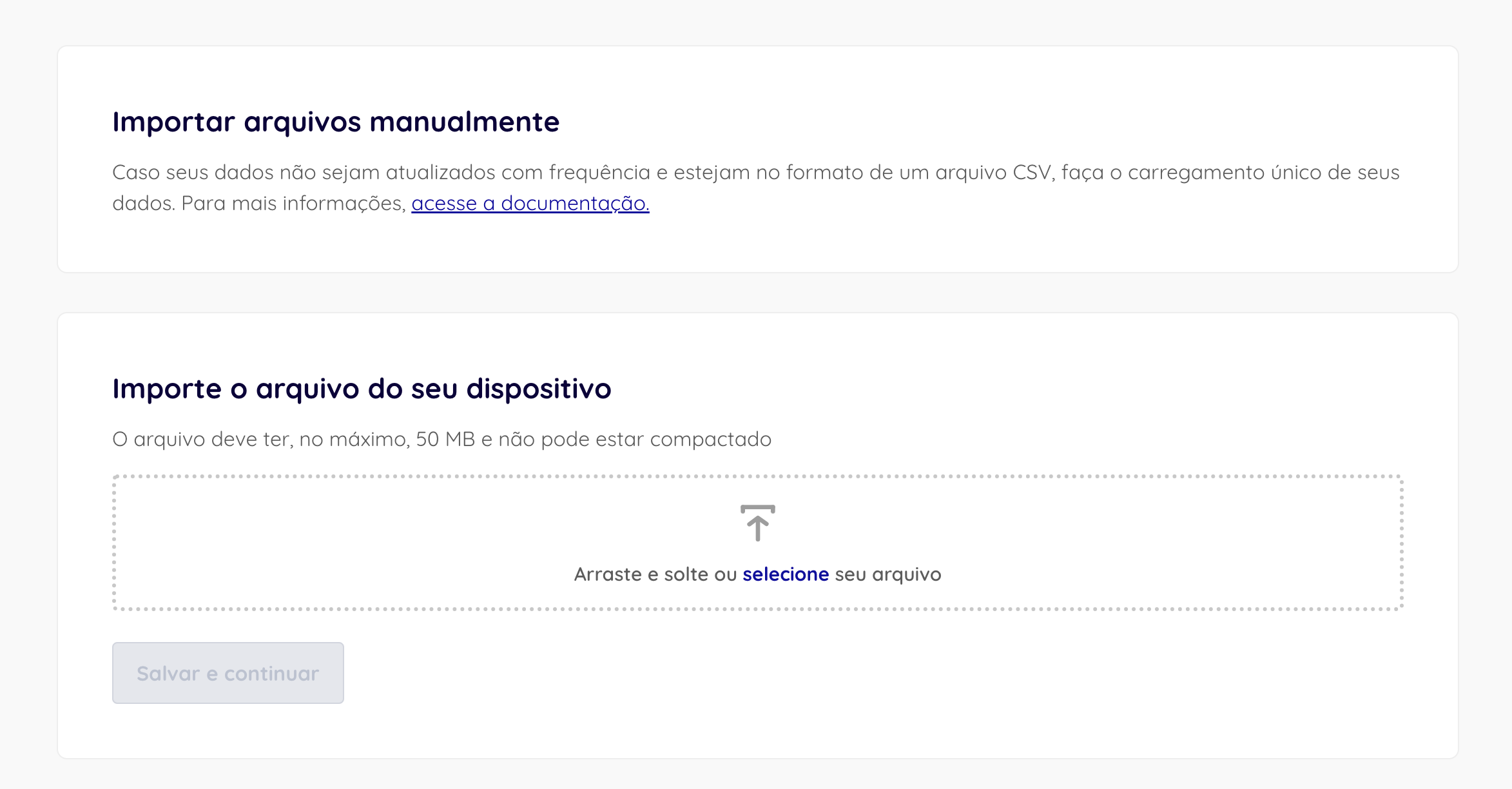
Center-aligned with border
- In the next step, you can edit the name of the imported file. Description is a mandatory field, so it will be possible to understand the context of the file in the best possible way later.
- In the file settings, define the type of encoding - the Brazilian standard is UTF-8, the separator of the CSV characters, and whether it has a header.
c) Monitor Import
- Check the Status of the file extraction from your device:
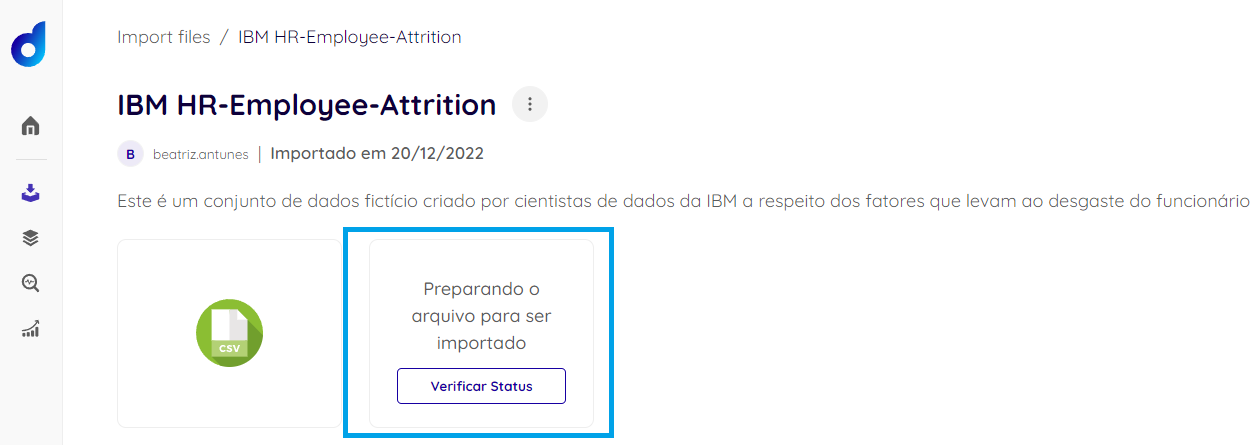
Center-aligned, 500px sizing, with border
- Monitor the import, that is, the loading of the file to Dadosfera:
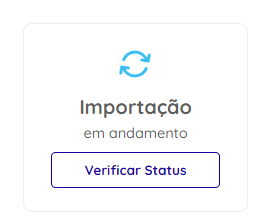
Center-aligned, 200px sizing
- Once the import is completed, it will be possible to access a preview of the data and access the complete dataset in the catalog by clicking on this card below:
Center-aligned, 220px sizing
Updated 6 months ago